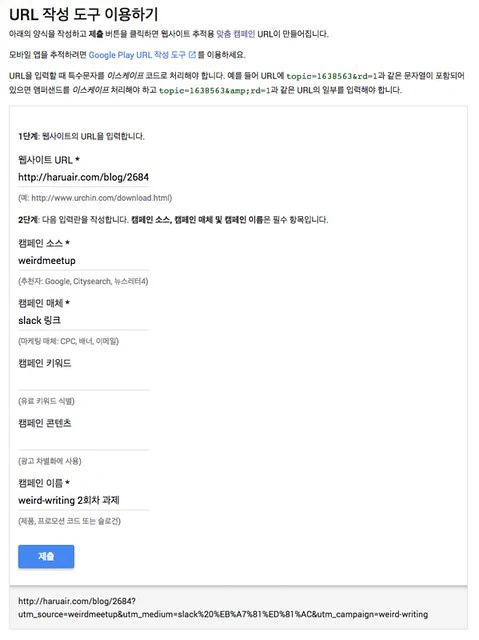
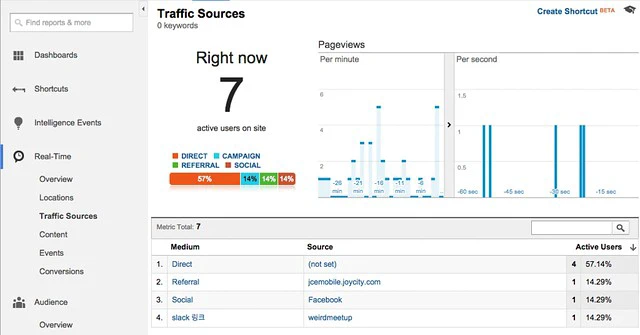
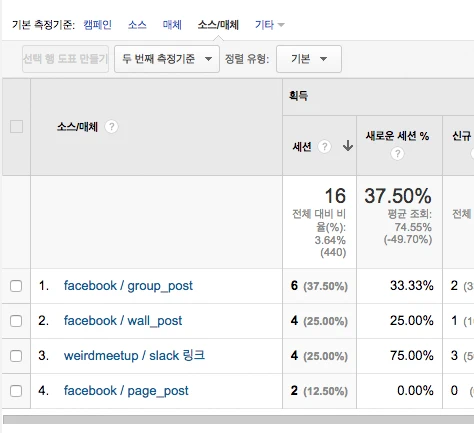
Micro-framework의 전성기라고 할 만큼 다양한 환경과 언어로 프레임워크가 쏟아지고 있다. PHP에도 micro-framework가 많이 나와 있는데1 최근 Laravel에서 Lumen을 발표했다. 발표 자료에서는 symfony2 기반인 silex보다 1.9배 빠르다고 하는데 문법적으로는 Silm과 상당히 유사한 느낌도 든다. 기존에 나왔던 프레임워크와 엄청나게 큰 구조 차이를 가지고 있는 것은 아니지만 Laravel과의 호환을 염두한 부분도 많다는 느낌을 받았다. 또한 구조적으로도 silex나 여타 기존에 나온 micro-framework 보다 훨씬 깔끔하고 미려하다는 느낌을 받았다.

이 포스트는 lumen 문서에서 쉽게 볼 수 있는 부분만 다뤘고 더 깊은 내용을 보고 싶다면 Lumen 공식 문서를 보는게 도움이 된다. Lumen는 PHP >= 5.4를 요구하며 Mcrypt, OpenSSL, mbstring, tokenizer 확장을 필요로 한다.
Lumen 설치
lumen을 설치하기 위해서는 composer가 설치되어 있어야 한다.
lumen을 사용해 프로젝트를 시작하는 방법은 lumen installer를 사용하는 방법과 composer의 create-project로 생성하는 방법이 있다. 결과물은 동일한데 installer 속도가 더 빠르다.
composer.json, phpunit.xml 등 단순한 스캐폴딩을 함께 제공한다.
Lumen Installer
다음 명령어로 Lumen Installer를 설치한다. 이 installer는 커맨드라인 환경에서 lumen 프로젝트를 시작할 수 있도록 기능을 제공한다.
composer global require "laravel/lumen-installer=~1.0"
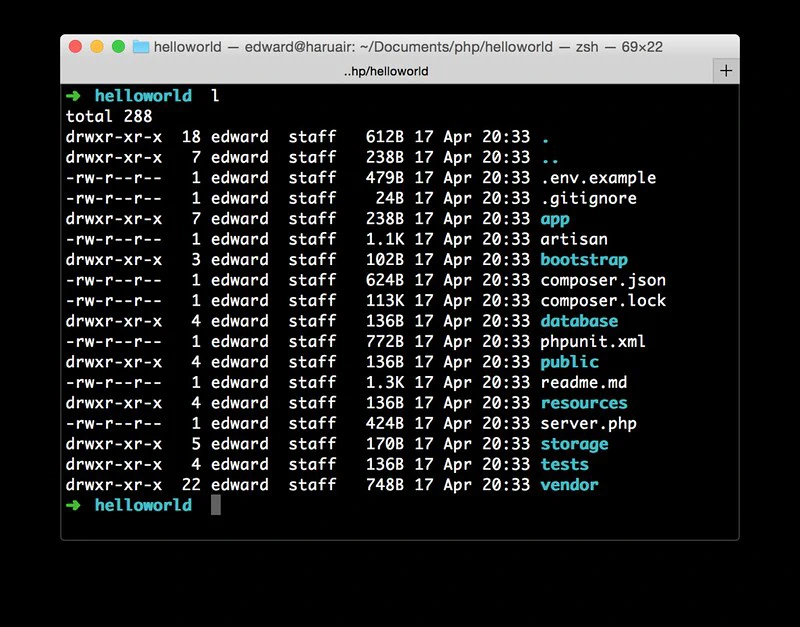
설치가 완료되면 lumen new 명령어로 프로젝트를 생성할 수 있다. 여기서 helloworld라는 이름으로 프로젝트를 생성했다.
lumen new helloworld
다음과 같이 프로젝트가 생성된 것을 확인할 수 있다.
composer
위 인스톨러를 사용할 수 없다면 composer create-project 생성할 수 있다.
composer create-project laravel/lumen
설정하기
lumen은 laravel과 다르게 모든 설정을 .env에 저장한다. 쉽게 활용할 수 있도록 .env.example 템플릿이 제공된다. 데이터베이스, 캐시, 큐, 세션과 관련한 설정값을 지정할 수 있다. 설정에서 가장 먼저 할 일로 해당 템플릿을 열어 APP_KEY에 32자 무작위 문자열을 입력한 후 .env로 저장한다.
URL 설정
Apache 환경을 사용하고 있다면 public/.htaccess를 활용할 수 있고 Nginx에서는 다음과 같이 설정할 수 있다.
location / {
try_files $uri $uri/ /index.php?$query_string;
}
HTTP 라우팅
라우팅 기초
route는 app/Http/routes.php에 작성한다. 여타 micro-Framework과 크게 다르지 않은 문법이다.
$app->get('/', function() {
return 'Hello World';
});
$app->post('foo/bar', function() {
});
$app->patch('foo/bar', function() {
});
$app->put('foo/bar', function() {
});
$app->delete('foo/bar', function() {
});
이렇게 생성한 route에서 URL을 다른 곳에서 사용하고 싶다면 url 헬퍼를 쓴다.
$list_link = url('foo');
router에서 파라미터는 다음과 같이 사용한다.
$app->get('user/{id}', function($id) {
return 'User '.$id;
});
$app->get('user/{name:[A-Za-z]+}', function($name) {
// do something
// 이 문법은 라라벨과 호환되지 않는다.
});
컨트롤러와도 쉽게 연결할 수 있다.
$app->get('user/{id}', 'UserController@showProfile');
위 route와 같이 복잡한 URL 구조를 가지고 있다면 route에 as로 별칭을 지정해 쉽게 활용할 수 있다.
$app->get('user/profile', ['as' => 'profile', function() {
}]);
$app->get('user/dashboard', [
'as' => 'dashboard',
'uses' => 'UserController@showDashboard'
]);
이제 위 route는 profile이라는 이름으로 활용할 수 있다. 파라미터가 있는 경우는 두번째 파라미터에 array로 값을 넣으면 된다.
$url = route('profile');
$redirect = redirect()->route('profile');
$profile_url = route('profile', ['id' => 1]);
라우팅 그룹 묶기
route를 그룹으로 묶어 미들웨어나 네임스페이스를 지정할 수 있다. 여기에서 $app->group()를 활용한다.
Closure를 기반으로 한 미들웨어는 다음과 같이 사용할 수 있다.
$app->group(['middleware' => 'foolbar'], function($app) {
$app->get('/', function() {
});
$app->get('user/profile', function() {
});
});
namespace로 특정 네임스페이스에 있는 컨트롤러를 불러 활용할 수 있다.
$app->group(['namespace' => 'Admin'], function() {
// "App\Http\Controllers\Admin" 네임스페이스에 있는 컨트롤러
});
HTTP 예외 발생하기
abort 헬퍼를 이용한다. 응답을 같이 보내줄 수도 있다.
abort(404);
abort(403, 'Unauthorised action.');
이 헬퍼는 상태 코드와 함께 Symfony\Component\HttpFoundation\Exception\HttpException 예외를 던진다.
뷰
뷰는 resources/views에 php 파일로 저장한다.
<!doctype html>
<html>
<head>
<title>Welcome!</title>
</head>
<body>
<h1>Hello, <?php echo $name; ?></h1>
</body>
</html>
다음과 같이 사용할 수 있다.
$app->get('/', function() {
return view('greeting', ['name' => 'James']);
});
$app->get('/admin', function() {
return view('admin.dashboard', $data);
});
데이터 바인딩을 배열로 넘길 수 있지만 with 메소드나 매직 메소드를 활용할 수도 있다.
$view = view('greeting')
->with('name', 'Edward')
->with('age', 20)
->withLocation('Jeju'); // 매직 메소드
컨트롤러
규모가 커지면 routes.php 파일 하나로만 로직을 다루는 것보다 컨트롤러를 활용해서 구조화하는 것이 낫다. 컨트롤러로 HTTP 요청을 조작하는 로직을 쉽게 묶을 수 있다. 컨트롤러는 app/Http/Conterollers에 저장한다.
컨트롤러는 App\Http\Conterollers\Controller 기초 클래스를 필수적으로 상속해야 한다. 기본적인 컨트롤러는 다음과 같다.
<?php namespace App\Http\Controllers;
use App\User;
use App\Http\Controllers\Controller;
class UserController extends Controller {
public function showProfile($id)
{
return view('user.profile', ['user' => User::findOrFail($id)]);
}
}
이 UserController를 라우터에서 다음과 같이 연결할 수 있다.
$app->get('user/{id}', 'App\Http\Controllers\UserController@showProfile');
의존성 주입
Lumen과 Laravel의 서비스 컨테이너는 타입 힌트를 통해 의존성을 해결해준다. 생성자 주입, 메소드 주입 둘 다 사용 가능하다. 다음 코드는 생성자의 타입 힌트 UserRepository, store 메소드의 타입힌트 Request로 의존성이 주입되는 예제다.
<?php namespace App\Http\Controllers;
use App\Http\Controllers\Controller;
use App\Repositories\UserRepository;
use Illuminate\Http\Request;
class UserController extends Controller {
protected $users;
public function __construct(UserRepository $users)
{
$this->users = $users;
}
public function store(Request $request)
{
$name = $request->input('name');
}
}
미들웨어
HTTP 미들웨어는 HTTP 요청과 응답을 제어할 수 있도록 돕는 구조로 micro-Framework에서는 흔히 사용되고 있다. (Python의 uWSGI, .Net의 OWIN) 미들웨어는 app/Http/Middleware에 위치한다.
미들웨어를 활용하기 위해 구성해야 하는 메소드는 handle이다.
<?php namespace App\Http\Middleware;
class OldMiddleware {
public function handle($request, Closure $next)
{
if ($request->input('age') < 200) {
return redirect('home');
}
return $next($request);
}
}
미들웨어로 HTTP 요청과 응답을 모두 제어할 수 있는데 $next($request)를 기준으로 그 앞에서는 요청을 제어하고 뒤에서는 응답을 제어할 수 있다.
다음은 요청을 제어하는 미들웨어로 이 내용을 실행한 후 어플리케이션에 접근하게 된다.
<?php namespace App\Http\Middleware;
class BeforeMiddleware implements Middleware {
public function handle($request, Closure $next)
{
return $next($request);
}
}
다음은 응답을 제어하는 미들웨어 예시로 어플리케이션에서 처리가 끝난 후 클라이언트에게 전달되는 응답을 제어할 수 있다.
<?php namespace App\Http\Middleware;
class AfterMiddleware implements Middleware {
public function handle($request, Closure $next)
{
$response = $next($request);
return $response;
}
}
Service Provider와 Service Container
Lumen은 Service Provider와 Service Container로 기초를 구성하고 있다. Service Provider는 어플리케이션을 시작하기 전에 준비해야 할 작업을 처리할 수 있다. bootstrap/app.php를 열어보면 $app->register() 메소드를 확인할 수 있는데 이 메소드를 통해 추가적인 service provider를 등록할 수 있다.
Service Container는 클래스 간의 의존성을 해결하기 위한 도구로 생성자 또는 “setter” 메소드를 통해 의존성을 주입해준다. $app->bind(), $app->singleton()을 통해 resolver를 등록할 수 있다. 컨테이너에서 의존성을 주입 받기 위해서는 $foobar = $app->make('FooBar'); 방식으로 make 메소드를 사용하는 방법이 있고, 앞서 살펴본 방식인 생성자나 개별 메소드에서 타입 힌팅을 이용해 의존성을 주입할 수 있다. 자세한 내용은 각 문서를 참고하자.
Micro-framework지만 그 말이 무색할 만큼 현대적인 PHP 개발에서 필요한 필수적인 요소는 모두 포함된 강력함을 보여주고 있다. 이 포스트에서 자세하게 다루진 않았지만 많은 서비스도 제공하고 있으며 기존에 laravel을 사용하고 있다면 더 간편하게 사용할 수 있을 것이라 본다. 지금까지 나온 micro-framework 중에서는 가장 마음에 드는 구성이라 차기 프로젝트에서 사용하는 것을 생각해보고 있다. 앞으로 기대가 많이 되는 프레임워크다.
PHP 기반의 Micro Frameworks 정리 ↩