이런저런 글을 올리는 공간입니다.
글목록
장인어른
올해 초 장인어른께서 야속하게도 소천하셨다.
장인어른은 정말 평생 일만 하셨다. 차량정비를 하셨는데, 주6일 출근하시고도 주말엔 교회 이웃들 차를 봐주셨다. 덕분에 주말엔 교회처럼 붐볐고 장인어른의 유일한 휴일도 출근한 날과 다르지 않았다. 그렇게 수 십 년 일하셨으니까, 은퇴 후에는 좀 편히 쉬고 즐겁게 시간 보내시길 온가족이 바랐다. 여행도 다니시고, 맛있는 것 찾아 드시고, 은퇴하고 시간을 그렇게 보내는 주변 사람들을 보며 그런 은퇴를 꿈꿨다.
은퇴 직후에 암 진단을 받으셨었다. 장모님도 암으로 오래 투병하셨지만 이제 일상생활에 지장이 없을 정도로 잘 지내고 계시니까, 우리도 모두 소망을 갖고서 치료를 이어갔다. 항암치료 후엔 경과가 좋을 때도 있고 하루 종일 누워계실 때도 있었다. 장기를 떼어 낸 이후에 투석도 시작했다. 점점 더 힘들어 하셨다. 음식도 도통 드시지 못했다.
우리 삶의 우선 순위도 당연히 달라졌다. 왕복 세 시간 거리를 매주 한 두 차례 다녀왔다. 나도 모든 걸 다 붙잡고 있을 수 없었다. 회사도 정리했고, 마지막 순간에는 학업도 잠시 미뤘다. 마음이 복잡했다. 내 일상을 잠시 미루는 것이 다시 건강해질 거라는 믿음을 놓는 기분이 들어서.
조금이라도 나아질 기미가 보일 때마다 모두가 기뻐했다. 잠시 나아졌다, 나빠졌다를 반복했다. 그러다 병원에 입원하셨고, 기쁜 날보다 눈물 고이는 날이 점점 많아지다가, 더이상 할 수 있는 부분이 없어 집으로 모셨다. 그러고 얼마 지난 후에 집에서 눈을 감으셨다.
추모예배는 장모님 다니시던 교회에서 해주셨다. 장모님은 본당에서 하면 큰 공간에 너무 빈 자리가 많을까 걱정하셨는데, 걱정이 무색하게도 많은 분들이 함께 해주셨다. 아픔 없는 하늘나라 가셨으니까, 우리도 다시 만날 날 기약하자는 말씀이 유난히 모난 돌처럼 느껴졌다. 신앙인으로 당연한 이야기를 들으면서도 계실 때 잘해드리지 못한 순간들이 왈칵 쏟아졌다.
장인어른은 처제네가 있는 텍사스로 모셨다. 미국식이라서, 하관 전에 마지막으로 얼굴을 보는 시간이 있었다. 한동안 아프고 힘든 모습만 봐서 그런지 평온한 모습이 낯설었다. 처제네 친정과 함께 말씀과 기도를 나누며 하관식을 마무리했다. 그러고서 모두 밥먹으러 근처 순두부집을 갔다. 모든 게 끝나고 나니 뭐가 그리 급하셨나 화도 나고, 본인이 뭘 어떻게 할 수 있는 것도 아닌데 나는 뭘 원망하나, 하는 앞뒤 없이 복잡한 생각 속에서 하얀 순두부를 떠 먹었다.
나조차도 문득문득 생각나는 장인어른 모습에 가슴이 답답했다. 울다가 자는 날도 많았다. 아내나 처제나 장모님은 어느 정도일지 짐작도 할 수가 없었다. 시간이 흐르면 좀 괜찮아지겠지, 그렇게 생각하는 것 말고는 감정을 추스릴 방법이 없었다. 몇 달이 지났고 조금은 나아졌을까, 아직도 잘 모르겠다. 여전히 가슴이 죄어오는 기분이 들지만, 괜찮아지겠지. 민경씨는 회사에 바빴고 나는 다시 학교로 돌아갔다. 장모님은 처제네와 우리집을 오가며 계시다가 처제네 둘째 출산으로 당분간은 거기서 지내시기로 했다.
이 어려운 순간에도 고마운 손길이 많았다. 힘든 시간 위로해주신 분들께 너무나도 감사하고. 이웃과 공동체를 돌보는 일이 얼마나 대단한 일인지. 아직도 우리의 일상으로 돌아가는 날은 멀거나 아니면 다시는 예전같아 질 수 없을거란 생각이 들지만, 그래도 언젠가는 괜찮을 거란 용기를 얻어간다. 우린 서로가 있고 서로에게 위로와 힘이 되어 줄 수 있으니까. 이웃이든 가족이든.
Father’s day라서 장인어른 보러 가는 길이다. 매년 숯불에 갈비 구웠었는데, 거기서도 좋아하시는 것 잘 드시고 계셨으면 좋겠다.
마트가서 우유 하나 사고 아보카도 있으면 6개 사와
"마트가서 우유 하나 사고 아보카도 있으면 6개 사와" 요즘 숏폼으로도 많이 돌아다니길래 재미삼아서. 가장 먼저 코드를 작성하기 전에 요구사항을 잘 읽는다.
- 마트가서: 가야 할 장소
- 우유 하나 사고: 품목과 수량, 수행해야 할 작업
- 사고: AND
- 아보카도: 품목
- 있으면: 조건 (있으면 사고 없으면 안사도 되는)
- 6개 사와: 수량과 수행해야 할 작업
정리하면
- 구입할 물건과 수량: 우유 1개, 아보카도 6개
- 구입해야 하는 장소: 마트
- 조건: 아보카도는 있으면 구입
명시되지 않은 상황과 조건은 다시 확인이 필요하다.
- 우유는 없고 아보카도만 있으면 아보카도만이라도 사올지
- 마트 간 곳에 우유가 없으면 다른 마트라도 가서 우유 사와야 하는지
// 마트가서 우유 하나 사고 아보카도 있으면 6개 사와
function okJob1(person, place) {
person.purchase("milk", 1, place)
if (place.has("avocado")) {
person.purchase("avocado", 6, place)
}
}
function okJob2(person, place) {
person.purchase("milk", 1, place)
place.has("avocado") && person.purchase("avocado", 6, place)
}
function buggyJob(person, place) {
// 아보카도가 있으면 우유 6개 사온다는 설정은
// 코드로 봐도 좀 이상한 결정인 것 같은데
// 세상은 넓고 요구사항은 다양하니까...
person.purchase("milk", place.has("avocado") ? 6 : 1, place)
}
대략 이런 구현을 사용해서 일을 잘 정리했는지 테스트해본다.
class Location {
constructor(name, inventory) { this.name = name; this.inventory = inventory; }
has(item) { return this.inventory.includes(item); }
}
class Person {
constructor(name) { this.name = name; }
purchase(item, count, location) {
console.log(`${this.name} purchased ${count} ${item} from ${location.name}.`)
}
}
const memberOfHousehold = new Person("Spouse");
const marketWithAvocado = new Location("market", ["milk", "avocado"]);
const marketWithoutAvocado = new Location("market", ["milk"]);
okJob1(memberOfHousehold, marketWithAvocado);
// Spouse purchased 1 milk from market.
// Spouse purchased 6 avocado from market.
okJob1(memberOfHousehold, marketWithoutAvocado);
// Spouse purchased 1 milk from market.
okJob2(memberOfHousehold, marketWithAvocado);
// Spouse purchased 1 milk from market.
// Spouse purchased 6 avocado from market.
okJob2(memberOfHousehold, marketWithoutAvocado);
// Spouse purchased 1 milk from market.
buggyJob(memberOfHousehold, marketWithAvocado);
// Spouse purchased 6 milk from market.
buggyJob(memberOfHousehold, marketWithoutAvocado);
// Spouse purchased 1 milk from market.
간 김에 이것저것 장을 많이 봐서 올 것 같은데. 내일 아침은 아보카도 토스트 해야겠다.
샤오미 미밴드 8 구입기
애플워치를 한동안 사용했지만 도무지 매일 충전하는 일이 익숙해지지 않았다. 온갖 알림 덕분에 모든 것을 놓치지 않고 살게 하지만 눈 앞에 있는 일에 좀 소홀해지는 기분도 들어서, 결국엔 시계 기능만 잘하는 카시오 시계를 한동안 차고 다녔다. 그러다 미밴드에 대해 우연히 듣고는 이 시계는 좀 괜찮지 않을까 싶어서 구입했다.
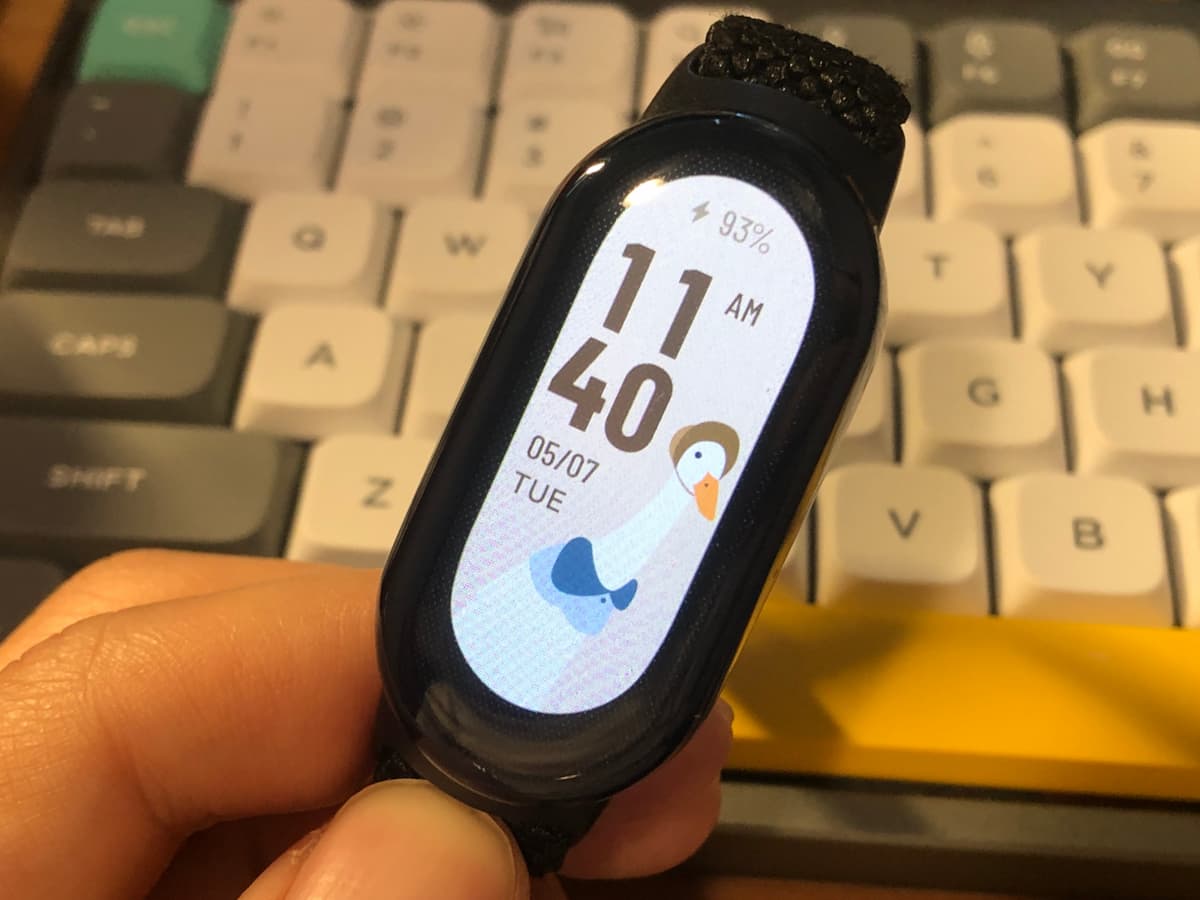
- 가격이 애플워치에 비하면 정말 저렴한 편이다. 케이스랑 시계줄을 서드파티로 구입했는데 악세서리 가격이 시계 가격이랑 같았다.
- 가볍다. 애플워치는 항상 찰 때마다 거추장스러운 느낌이 있었는데 그냥 고무밴드 끼고 있는 기분이다.
- 배터리가 오래 간다. 대부분의 기능을 켜고 끌 수 있어서 중요하지 않은 기능을 끄면 정말 오래 사용할 수 있다. 게다가 충전도 꽤 빠른 편이라서 샤워하고 오는 사이에 완전 충전이 가능하다. 일주일에 한 번 정도 충전하는 걸로 충분하다.
- 워치페이스가 다양하다. 안드로이드를 사용하면 직접 워치페이스를 만들어서 넣는 것도 가능하다는데 그러지 않아도 충분히 이것저것 많다.
- 측정 정확도는 엄청 정확하진 않다는데 의료장비가 아니니까 그런 기대는 크게
안하고. 그래도 대략적으로 얼마나 잤나, 얼마나 걸었나는 정도는 적절하게
측정한다.
- 애플 건강앱에 데이터도 잘 연동된다.
- 알람은 진동으로 동작한다. 진동 크기는 밴드를 얼마나 꽉 끼냐에 따라서 편차가 꽤 큰 것 같다.
알림 메시지가 가끔 잘 안온다는 얘기가 있던데 문자든 전화든 아무 알림도 안오게 설정하고 사용하고 있어서 그건 확인을 못해봤다. 조용한 웨어러블 기기로 쓴다면 전혀 부족하지 않아 만족스럽다.
2024 뉴욕 여행 기록
3월 27일부터 30일까지 3박 4일 (+1 레드아이) 일정으로 뉴욕 여행을 다녀왔다. 그동안 가정사에 큼직한 일이 줄줄이 있어서 어딜 가지 못하다가 조금은 갑작스럽게 리프레시 여행을 결정하게 됐다. 뉴욕은 민경 씨와 처음 만난 곳이라서 더욱 추억할 거리가 많았다.
오랜만에 하는 여행이라서 기대하는 마음보다도 얼떨떨함에 걱정이 조금 앞서기도 했었다. 둘 다 체력도 조금 유리인데다 잘 체하기도 해서 꽉 체운 일정을 우리가 잘 지킬 수 있을까 했는데 잘 짜인 계획 덕분에 유연한 대처도 가능했던 것 같다.
생각보다 사진을 많이 못찍었는데, 다음 스마트폰으로 교체하고 나면 더이상 카메라를 들고 다니지 않을 것 같기도 하다. 카메라 즐겁긴 하지만 점점 번거롭게 느껴지는게 아쉽다. 예전에 비해 또 사진에 대한 생각도 많이 달라지기도 했고.
계획할 때는 이게 마지막 뉴욕 여행이 될 것이란 얘길 하면서 일정을 짰는데 여행 후에는 우리 결국 못 본 곳들 많아서 적어도 다시 한 번은 와야겠다는 얘기를 했다.

커피
큰 기대 없던 곳까지도 커피가 맛있다니, 집에 와서도 뉴욕서 마신 커피 얘기한다.
- %Arabica NY 30 Rock: 이곳저곳에 매장이 많길래 늘 궁금했는데 숙소 바로 옆이라서 들렸다. 레드아이 직후에 마신 커피라서 기억이 좀 가물가물한데 무난한 편이었다.
- WatchHouse 5th Ave: 여기도 숙소 근처여서 MoMA 갔다가 들렸는데 아마 여행 중 간 곳 중에 가장 기억에 남는 곳이다. 가격대가 높긴 했지만, 브루커피 마저도 산미가 좋아 만족스러웠다.
- Pavé NYC: 숙소 근처였는데 아침 식사 겸 들렸다. 페이스트리도 꽤 괜찮고 커피는 산미가 강하진 않았지만 제공되는 음식과 잘 어울리는 곳이었다. 말차 까눌레 처음이었는데 정말 좋았다.
- Variety Coffee Roasters Upper east side: 이곳저곳 있는데 구겐하임 갔다가 들렸다. 고소함 정말 강하고 끝에 좋은 산미가 있었다. 춥다 못해 비가 온 날이었는데 카페인으로 센트럴 파크를 씩씩하게 걸었다.
- Bar Pisellino: 인스타그램에서 이뻐 보이길래 간단하게 아침 먹을 겸 들렸다. 이탈리아풍으로 꾸며둔, 조그맣고 귀여운 공간이었다. 점심 전부터 칵테일 마시는 사람도 꽤 있었지만 우린 크로아상이랑 샌드위치, 커피 다 깔끔하고 좋았다. 우린 언제 이탈리아 가보지 얘기 하면서.
- OSLO Coffee West Village: 사실 웨스트 빌리지에서 Pisellino에 갈 지 이 곳에 갈 지 고민하다가 지나가는 길 근처라서. 조그맣고 귀여웠다. 바디감 있는 쪽이긴 했지만 균형있는 맛이 좋았다.
- Drip Coffee Makers in Clark Street Station: 덤보에서 브루클린 다리 구경하고 동네 구경 삼아 걸어간 곳이다. 정말 지하철 역사 안에 있는 카페였다. 푸어 오버 해달라고 하니 몇 가지 선택지도 있었고, 역 오가는 사람들 사이에서 커피 내리는 걸 기다렸다. 뉴욕 지하철 답게 너저분한 분위기인데 이런 곳에서 카페를 한다니 너무나도 신기했고, 커피 내리는 사이에도 에스프레소 사가는 사람도 있고. 그렇게 내린 커피는 여행 내내 다시 얘기할 정도로 맛있었다.
- Birch Coffee Upper East: 메트로폴리탄 보고 나와서 마지막으로 마신 커피. 고소하고도 베리류 산미가 있어서 너무 좋았다. 게다가 카페에 레밍턴 케이크를 팔고 있어서 너무 신기했다.
음식
- Blue Willow: 맛있게 매운 사천 음식점. 예약 없이 갔다가 자리가 없길래 주문하고 픽업해서 숙소에서 먹었다. 우리 매운 음식 잘 먹지도 못하면서 너무 많이 시킨 거 아닌가 했는데 세상 깔끔하게 먹었다. 사천식 오이샐러드, 마파두부 등등 다 맛있었다!
- Gallaghers Steakhouse: 그래도 뉴욕이니까 스테이크하우스를 가봐야지 싶어서 유명하다는 곳으로 예약했는데... 분위기는 매우 좋았다.
- Magnolia Bakery: 민경 씨가 지난 번 왔을 때 분명 먹었다고 하는 바나나 푸딩인데 난 먹은 기억이 없다고 맨날 투닥거리던 곳. 그래서 이제 제대로 먹고 제대로 기억하기로 했다. 맛있었다! 푸딩이란 게 젤로 같은거 생각했는데 그건 또 아니구나 신기했다.
- Agi's Counter: 가까운 줄 알았는데 생각보다 멀어서 놀랐다. 브루클린 어딘가 있는데. 메뉴 너무 다 생소하고도 맛있었다. 멸치 얹은 데빌드 에그도 맛있었고 보보 치킨, 알감자 튀김에 올리브유 얹은 블루베리 치즈케익도. 모든 음식이 낯설 정도로 달랐는데 요즘도 자기 전에 이때 먹은 것 얘기한다.
- Corrado Bread & Pastry on Lex 90th: 메트로폴리탄 가기 전에 아침으로 먹었는데, 뉴욕집밥(?) 분위기로 오가는 사람들이 많았다.
전시/공연
- MoMA: 첫 뉴욕 방문 때에도 왔었는데, 그때보다도 훨씬 많은 인파가 있었다. 어느 공간에나 사람이 많아서 좀 정신 없이 구경하고 나왔다. 대신 스토어에서 이것저것 구경하고 책 살펴보는데 더 시간을 썼다.
- Guggenheim: 예전부터 꼭 가보고 싶었는데 상설 전시가 아닌 특별전을 하고 있어서 조금 아쉬웠다. 그래도 잘 보지 못하던 작품도 많아서 인상적이었다.
- The Metropolitan Museum of Art: ... 정말 방대했다. 이번이 마지막 뉴욕 여행이다 했는데 메트로폴리탄 때문에 또 와야겠다고 얘기했다.
- Wicked - Gershwin Theatre: 브로드웨이에서 뮤지컬 보는 게 지난 뉴욕 여행 때 마음에 걸렸다고 해서. 공연 본다고 줄 서 있는데 투덜거리던 사람들이 많아서 덩달아 짜증났는데 막상 들어가서 너무 즐겁게 봤다. 정말 모든게 초록초록했다! 초록색 덕후인 민경 씨는 에메랄드 시티로 이사가자며 초록색 꿈을 꿨다.
- Mahler Chamber Orchestra: Mitsuko Uchida - Carnegie Hall: 오케는 정말 오랜만이라서, 예전에 관악 부지런히 하던 것도 생각이 나고. 가슴뛰는 공연이었고 신선하고 재밌었다.
이곳저곳 이것저것
- Three Lives & Company Bookstore: 우연히 들어간 책방인데 사고 싶은 책을 또 잔뜩 살펴보다 왔다. 언제 다시 책 읽는 삶으로 돌아가지? 그것보다도 이것저것 사서 꽂아둘 공간을 갖고 싶은 마음도 컸다. 조그마한 책방인데 마음에 드는 책은 어찌도 그리 많았는지.
- Apartment Building from the TV Show Friends: 정말 프렌즈를 촬영하거나 한 것은 아니지만 매 에피소드마다 나오던 그 건물을 보고 왔다. 우리 말고도 사람 많았고 사진 찍는 사람도 많더라. 웨스트 빌리지 귀여웠고 정말 프렌즈 주인공들이 살고 있을 것 같은 동네였다.
- Brooklyn Bridge, Dumbo, Jane's Carousel: Past Lives를 재밌게 보기도 했어서 다녀왔다. 사람이 정말 많았지만 영화 내용도 또 새록새록 나고. 가기 전에 지하철을 반대 방향으로 타서 한 번 낼 돈을 두 번 내는 에피소드도, 나중에 생각하면 웃길 거야, 했는데.
- LEGO Store at Rockefeller center: 둘이 처음 뉴욕 왔을 때 들렸던 겸 해서 다녀왔다. 디자인만 하면 피겨 블럭에 출력해주는 서비스는 신기하고 재밌었다.
- MUJI: 산타모니카에 갈 때마다 종종 들렸는데 아쉽게도 폐점되어서 추억 삼아 숙소 근처에 있던 무지에 다녀왔다. 소소하게 잠옷과 이것 저것 구입. 그러고 나오니 뉴욕의 찍찍이를 잔뜩 봤다.
- Mure + Grand™: 귀엽고 핑크했던 스토어.
- Bounce: 짐 맡겨주는 서비스인데 덕분에 숙소로 다시 돌아가는 동선을 줄일 수 있었다. 우리 숙소에 불만이 많았던 탓에 짜증이 많이 나 있던 상태였는데. 여행 중 최고 유용했던 서비스.
40+20 작업법
40+20 작업법은 어떻게 하는 건가요?
- 하루에 몇 KMN을 하겠다고 정한다(예: 8KMN)
- 쪽지에 그 횟수만큼 숫자를 쓴다(예: ➀➁➂➃➄➅➆➇).
- 몇 시든 좋으니 정각에 자리에 앉는다(예: 오전 10시).
- 40분 후 알려주도록 설정된 타이머를 켠다.
- 40분간 집중해서 작업한다.
- 타이머가 울리면 무조건 일어난 뒤, 1KMN을 했다고 표시한다(예: ➊➁➂➃➄➅➆➇).
- 20분 쉬면서 다른 일을 한다.
- 다시 정각이 되면(예: 오전 11시) 무조건 자리에 앉는다.
- 4)~8)을 목표 횟수만큼 반복한다(예: ➊➋➌➍➎➏➐➑).
- 하루 일을 마감한다(예: 오후 6시).
40+20 작업법에서 기억할 점
- 일할 때 집중합니다.
- 쉴 때 긴장을 풉니다.
- 일할 때 다른 문제를 걱정하지 마세요.
- 쉴 때 일을 걱정하지 마세요.
- 가급적 정각에 시작하세요.
- 앱에 의존하지 마세요.
- 하루에 10KMN 이상 하지 마세요.
-- 40+20 작업법
간단하게 현재 상황과 남은 일을 확인할 수 있는 시스템을 구축하는 접근 방식이 너무나도 마음에 든다. 외부 의존도를 낮추면서도 단순하게 작은 종이에 할 일을 적는 방법은 정말 해야 할 일에 힘을 집중할 수 있게 한다.
블로그 업데이트
어쩌다보니 블로그 업데이트를 연례 행사처럼 치루고 있다.
그동안 Gatsby를 잘 사용하고 있었지만 걷어내기로 했다. netlify 인수 이후엔 업데이트 자체도 상당히 정체된 상황이다. 새 버전에 대한 이야기가 있긴 하지만 수많은 플러그인이 동시에 관리되고 업데이트 해왔던 그간의 방향성을 봤을 때 조금 의구심이 들 수 밖에 없는 상황이다. 거기에다 Gatsby Cloud도 접은 것 보면 사용자로서는 좀 김이 빠진다. 정말 좋아하는 프로젝트고 프로덕트였는데 프로덕트의 성숙도와는 달리 순식간에 불투명해져버린 상황이 많이 아쉽다.
react 기반의 정적 사이트 생성기를 계속 사용할까 찾아봤다. Astro가 요즘 유행이기도 하고 Vercel 제품도 사용해보고 싶긴 하지만... 1) 웹브라우저의 기본적인 사이클과 잘 맞지 않는 기분이 종종 들었고 (아무래도 웹사이트니까 SPA같은 느낌이 드는게 묘하게 어색한 그런 기분), 2) 마크다운에 마음대로 인라인 스크립트나 스타일을 넣는 일도 좀 불편한 기분이고, 3) 간단한 html을 넣으려고 이런 저런 컴포넌트를 오가야 하는 일도 조금 번거로웠다. 물론 react 문제 아니고 내가 구성한 방식의 문제겠지만서도.
다른 정적 생성기를 사용할까 찾아보다가 그냥 간단하게 만들기로 했다. 페이지네이션 없이 그냥 목록만 제공할 거니까, 복잡하게 생각하지 말고 그냥 생각 가는데로 간단하게 만들기로 했다.
그동안 remark.js를 gatsby 통해서 잘 사용해왔으니까 이젠 직접 사용하기만
하면 될 것 같았다. 이미 라우팅은 각각 마크다운 파일에 정의된 frontmatter를
사용해서 만들어내고 있었기 때문에 frontmatter만 읽어 처리할 수 있으면 되는
상황이었다. remark.js과 여러 플러그인 통해서 별 문제 없이 구현할 수 있었다. 사실
gatsby 대부분 마크다운과 관련된 플러그인은 remark.js의 플러그인을 랩핑한
것이라서, 좀 더 날 것의 형태로 사용할 수 있다는 것은 오히려 장점이었다.
템플릿도 별도 엔진을 사용할까 하다가도 새로운 템플릿 문법을 보고 짜는 것도 번거롭고 이미 리터럴을 잘 쓰고 있으니 간단하게 템플릿 리터럴로 구현했다. 페이지 컨텐츠는 라우팅과 분리했지만 템플릿은 라우팅을 기준으로 불러오게 해서 페이지마다 스타일을 바꾸기 쉽게 만들었다. 그 외에도 sitemap.xml, RSS 피드, 리다이렉션, 이미지 처리 등 필요한 요소도 추가했다.
아직 별도의 캐시를 넣은 것도 아닌데 2~3분 걸리던 빌드가 30초대로 내려왔다. 빌드 로그를 보면 빌드 자체는 금방인데 필드 환경을 불러오는 시간이 꽤 길었다. netlify에서 cloudflare pages로 변경하고 싶은데 cloudflare pages는 빌드 시간 제한이 아니라 횟수 제한이라서 사이트가 좀 더 정리되면 그때 옮길 생각이다.
js 템플릿 리터럴을 이용한 템플릿 함수 만들기
블로그를 변경하면서 간단한 템플릿 엔진이 필요했다. 템플릿 엔진을 사용하려고
살펴보니 새 문법을 배우는 것도 번거롭고 정말 작은 부분 때문에 의존성을 추가하는
것도 별로 맘에 들지 않았다. 그동안 잘 사용해온 템플릿 리터럴을 그냥 사용할
방법은 없을까 찾아보다가 Function 생성자를 사용해서 다음처럼 작성할 수
있었다.
"use strict";
function template(html, params = {}) {
const keys = Object.keys(params);
const ps = keys.map(k => params[k]);
return new Function(
...keys,
'return (`' + html + '`)')
(...ps);
}
Function 생성자는 파라미터 목록과 함수 내에 들어갈 내용을 문자열로 받고 그
함수를 반환한다. 위에서 보면 전달한 params에서 키 값을 수집해 함수를
생성하는 일에 사용하고 또 키 이름 순서에 맞게 ps 배열을 만들어 함수에
전달했다.
이제 html로 문자열을 전달하면 템플릿 리터럴로 이용할 수 있다.
const welcomePage = '<h1>${name}님 환영합니다.</h1>'
template(welcomePage, {name: '거북이'})
// "<h1>거북이님 환영합니다.</h1>"
다만 "`" 문자 사용에 주의해야 한다.
const welcomePage = '<h1>\\`${name}\\`님 환영합니다.</h1>'
template(welcomePage, {name: '거북이'})
// "<h1>`거북이`님 환영합니다.</h1>"
다른 도움 함수
부분함수도 손쉽게 만들 수 있다.
function partial(html) {
return function render(params) {
return template(html, params);
}
}
const accountPage = '<button>${name}님의 계정 정보</button>'
const accountPartial = partial(accountPage)
const me = accountPartial({name: '나'})
// "<button>나님의 계정 정보</button>"
const koala = accountPartial({name: '코알라'})
// "<button>코알라님의 계정 정보</button>"
템플릿 함수가 필요하다면 다음처럼 params에 함께 전달할 수 있다.
const balance = () => 3000 // 또는 좀 더 복잡한 코드
const balanceInfo = template('<strong>잔고: ${balance()}</strong>')({balance})
nodejs에서 사용하고 있기 때문에 nodejs의 모듈을 사용해 html을 불러오는 함수를
다음처럼 작성했다. 또한 템플릿 내부에서 별도의 파일을 불러올 수 있도록 load
함수를 경로 맥락과 함께 템플릿 내로 전달했다.
import fs from 'fs'
import path from 'path'
function load(filename, basePath = '.') {
const dirname = path.dirname(filename);
const html = fs.readFileSync(path.join(basePath, filename));
const partialHtml = partial(html);
return function loadPartial(params) {
return partialHtml({
...params,
load: function loadFromSubDir(filename) {
return load(filename, dirname);
}
})
}
}
<!-- ./templates/index.html -->
<h1>안녕하세요!</h1>
${load('./partials/info.html')({user})}
<!-- ./templates/partials/info.html -->
<p>${user.name}님의 계정 정보</p>
load('./template/index.html')({user: {name: '당근'}})
// "<h1>안녕하세요!</h1>\n\n<p>당근님의 계정 정보</p>"
템플릿 내에서 다른 유틸리티 함수가 더 필요하다면 위 함수와 같이 더 추가하면 되겠다.
보안 고려하기
사용자 입력을 직접 템플릿에 사용하는 것은 당연히 위험하다! 상황에 맞게 적절한 예비 조치가 필요하다.
function sanitize(text) {
return text.replace(/[^ㄱ-ㅎ|가-힣|a-z|A-Z|0-9| ]+/gi, "")
}
template(
"<p>${sanitize(name)}님 안녕하세요!</p>", {
name: "<strong>헤헤</strong>",
sanitize,
})
// "<p>strong헤헤strong님 안녕하세요!</p>"
이렇게 작은 템플릿 함수를 작성해봤다. 템플릿 리터럴을 활용하면 몇 줄 안되는
코드로도 템플릿 함수를 구현할 수 있었다. 간단한 수준에서라면 이 함수로도 충분히
활용 가능하겠지만 이 접근 방식의 한계(Function 내에서 바깥 스코프에 접근할 수
있는 등)로 보안 문제가 발생할 수 있다. 이런게 가능하다 정도로만 이해하고 제대로
된 라이브러리를 활용하는 것이 더 바람직하다.
Google Chrome PDF 뷰어를 Mozilla PDF.js로 교체하기
Google Chrome를 주로 사용하고 있는데 언제부터인지 브라우저 내 PDF 뷰어가 엄청 느려졌다. Mozilla의 pdf.js가 Chromium 확장을 제공하고 있어서 설치해봤는데 만족스럽다. Manifest V2로 작성된 확장이라서 크롬 웹 스토어에 있는 버전은 더이상 관리되지 않는 것 같다. 그래도 직접 빌드를 한 경우엔 아직까지도 문제 없이 설치할 수 있다.
$ git clone https://github.com/mozilla/pdf.js.git && cd pdf.js
$ npm install --global glup-cli
$ npm install
$ glup chromium
Google Chrome에서 chrome://extensions를 연 후 좌측 상단에 Load unpacked 버튼을 클릭, 그리고 pdf.js 폴더 내에 build/chromium을 선택하면 확장을 설치할 수 있다. Firefox에 내장되어 있는 pdf 뷰어와 동일하게 동작한다.
화성에서 본 지구
Earth from Mars – NASA: Climate Change: Vital Signs of the Planet을 번역했습니다.

이 사진은 NASA의 큐리오시티 로버가 화성의 표면에서 바라본 지구의 모습을 담고 있습니다. 화성의 밤하늘에서 어느 별보다도 밝게 빛나고 있습니다. 지구는 사진 가운데서 약간 좌측에 밝은 점이며 그 점 바로 아래에 있는 달도 보입니다. 2013년 8월 6일에 화성에 착륙한 큐리오시티는 그동안 화성에 보낸 탐사 차량 중 가장 크고 발전된 모델입니다. 주변의 지질 분석과 함께 미생물 생장에 적합한 환경을 갖고 있었는지 증거를 연구하고 있습니다.
연구원은 큐리오시티의 마스트 카메라(Mastcam) 좌측 카메라를 이용해 탐사 시작 529일, 일몰 80분 후 이 장면을 촬영했습니다. (지구 시간으로는 2014년 1월 31일). 이미지는 우주 방사선에 의한 현상을 제거하는 후처리 과정을 거쳤습니다. 사람이 화성에 서서 눈으로 직접 봤다면 지구와 달은 명확하게 분리되어 보이는 두 '별'로 보일 것입니다. 큐리오시티가 이 사진을 촬영했을 때 지구는 화성으로부터 9천 9백만 마일, 1억 6천만 킬로미터 떨어져 있었습니다.
이 사진은 "멀리서 본 지구" 사진 컬랙션에 추가되었습니다. 우리는 우주에서 어떤 공간에 살고 있는지에 대해 독특한 관점을 제공합니다.
크레딧: NASA Jet Propulsion Laboratory-Caltech/Malin Space Science Systems/Texas A&M University. 출처: NASA Jet Propulsion Laboratory.
1/46 페이지