2016년 들어온 지 얼마 되지 않은 것 같은데 벌써 시간이 이렇게 지났다. 상투적이지만 어째 한해 한해 더 빠르게 지나가는 기분이다. 올해는 바쁘다는 핑계로 경험을 글로 정리하지 못했는데 아무래도 저지른 일이 많다보니 한번에 풀어내기 쉽지 않은 탓도 있는 것 같다. 이상한모임에서도 올해 배운 것이라는 주제로 대림절 달력이 진행되고 있는데 달력에 매일 올라오는 글을 보면서 더 미루지 말고 조금이라도 정리해보자는 마음을 먹게 되었다.
올해 했던 일 중 하나가 도서 번역이었다. 이 글은 번역 과정에서 겪었던 경험과 생각을 정리한 포스트다. 번역을 하기 전에 막연하게 생각했던 부분도 실제 과정에서 겪기도 했고 생각과 전혀 달랐던 부분도 있었다. 출판이나 번역 쪽에 오래 계셨던 분이 읽기에는 너무 사소한 이야기일지도 모르겠지만 막 시작하는 입장에서 겪고 생각했던 부분을 정리해보려고 한다.
진행 과정
올해 2월에 출판사에서 페이스북을 통해 연락을 받았다. Practical Vim이라는 도서 번역 의뢰였다. 2015년 말에 올렸던 글이 널리 퍼진 일이 있었는데 그때 블로그를 보고 연락을 주셨다고 했다. 전문적으로 번역을 하는 것은 아니었지만 블로그에 작게나마 글을 번역해서 자주 올리고 있어서 제안이 너무 반가웠다. 특히 Vim은 늘 사용하지만 제대로 사용한다는 자신이 없었는데 이 책을 번역하면 그 가려움도 긁을 수 있지 않을까 생각이 들었다.
하지만 내 번역에 대한 질이나 속도를 정확하게 모르기도 했고 시간이 얼마나 걸리게 될지 예측하기가 어려웠다. 또한 안해본 일에 대한 두려움도 있었고 제대로 번역되지 않은 책에 대해서 뒷얘기도 많이 들었던 터라 쉽게 결정을 내릴 수 없었다. 블로그야 번역 글이 잘못되었다면 수정하거나 다듬거나 모든 일이 내 마음대로 되는데 책은 전혀 그러지 못하니 겁이 앞설 수 밖에 없었다. 그래도 안하면 이런 기회가 언제 다시 올까 싶어서 하겠다는 의사를 전했다.
출판사에서도 계약 전에 일정 분량을 번역해서 보내달라고 했다. 번역 품질이나 속도를 가늠하기 위한, 일종의 면접이였다. 그렇게 여러 장 분량을 번역해서 며칠 후 메일로 발송했다. 몇 차례 추가적으로 다듬는 과정을 거친 후에 큰 문제가 없을 것 같다는 얘기를 듣고 계약서를 작성하게 되었다.
초벌 번역은 6월에 끝났고 첫 교정은 9월에, 두 번째는 11월 초에 마무리했다. 초반에 번역했던 부분과 후반에 번역한 부분을 비교하면 확실히 후반부가 자연스러웠다. 진행하는 동안 문장력이 상승했는지 어쩐건지 모르겠지만 품질이 일관적이지 않았던 탓에 편집자님이 고생을 많이 하셨다.
어려웠던 부분과 배운 점
모든 과정이 도구와의 씨름이었다. 초벌 번역에서는 Vim을 사용해서 작성했지만 원문의 다양한 양식을 반영하는데 쉽지 않았다. 첫 교정에서는 구글독스를 쓰려고 했는데 페이지 분량이 조금만 많아도 속도가 너무 느려서 윈도 노트북을 장만하고 MS 오피스 워드로 전환했다. 워드도 분량이 많아지면 상당히 느려지고 굳을 때가 생각보다 많았다. 작업 과정 중 도구 때문에 고민 안했던 적이 없었는데 디자인으로 옮겨진 후에 PDF 상에서 교정을 볼 때 가장 편하게 느껴졌다.
용어 번역이 쉽지 않았다. 사전적 의미로 옮기는 방식은 가장 쉽지만 기능의 의미를 쉽게 이해할 수 있는지, 오히려 한번 더 생각해봐야 하는 용어는 아닌지 계속 고민할 수 밖에 없었다. 두루 사용되는 용어로 번역해야 할 지, 아니면 음차로 표기를 할 지 단어 하나하나 넘어가기 쉽지 않았다. Vim에서만 사용되는 용어는 참고할 곳도 마땅치 않아서 어려웠다.
번역에 있어 일관성을 유지하는 일도 생각보다 품이 많이 든다. 키워드는 동일한 용어로 번역해야 하는데 영어다보니 이게 키워드로 사용한 것인지 아니면 일반 표현으로 작성한 것인지 모호한 경우도 있었다. 번역을 진행하면서 용어 사전을 만드는게 좋다는 이야기를 들었는데 책 자체가 팁이 나열된 방식이고 각 팁마다 연결된 팁이 언급되어 있어서 그때그때 키워드를 찾는 과정이 그다지 어렵지 않았다. 하지만 나중에 교정에서 많이 후회했다. 생각보다 번역 기간은 길어졌고 그 기간동안 기억이 많이 희미해져서 오가며 찾아보는 과정에 시간을 많이 소비했다.
앞에서도 이야기했지만 긴 글을 번역해본 경험이 없어서 시간 배분이 쉽지 않았다. 각 장, 파트마다 “대략적인” 기간을 산정했는데 너무 안일했다. 시작하기 전에 분량과 내용의 난이도를 판단해서 일별로 작업량을 명확하게 정리할 필요가 있다. 전업 번역가가 아니라면 이 과정이 정말 중요한 것 같다. 책에서 나눠진 팁 단위로 목표를 잡고 진행했는데 각 장이나 팁마다 분량이 각각이라 생각보다 목표에 맞춰 진행하기 어려웠다. 쪽으로 나눠서 하는게 훨씬 편했고 작업 분량 측정이나 목표 달성하는데 훨씬 쉬웠다.
번역에 신경썼던 점
블로그에 번역글을 올리는 것과는 확실히 무게감에서 차이가 있어서 교정에 노력을 많이 했다. 볼 때마다 말도 안되는 문장이 자꾸 보여서 겁이 날 지경이다. 번역과 교정에서 지키려고 노력한 몇 가지 규칙이 있었다. 사소한 부분이긴 하지만 내 스스로 역서를 읽을 때 불편하게 느꼈던 표현이라서 계속 염두하고 진행했다.
피동/사동 표현은 최소로 사용하려고 했다. 피동이 아니면 정말 어색한 경우 외에는 전부 능동으로 적었다. “비주얼 모드에서 영역 선택 기능이 제공된다.” 보다는 “비주얼 모드에서 영역 선택 기능을 제공한다.” 처럼 작성했다.
대명사는 좀 더 명확하게 하고 싶었다. It, this 같은 대명사가 반복되는데 “이 플러그인은”, “이 기능은” 식으로 옮겼다.
복수형 표현에 주의했다. Some of Vim’s commands are 식은 “Vim의 명령들 중에는” 보다 “Vim의 명령 중에는” 처럼 작성했다.
번역 과정 중에 번역에 관한 책을 몇 권 알게 되서 읽어보려고 했는데 번역 사이사이 베타리딩, 이상한모임 행사, 회사일, 호주 체류 관련 업무 등등 수많은 일이 있어 도저히 읽을 여유가 없었다. 위시리스트에 있는 책은 다음과 같다. 각각 읽은 분들 후기를 보면 읽고 나서 번역했으면 얼마나 좋았을까 생각하며 적어뒀다.
내 문장이 그렇게 이상한가요?
번역의 탄생
번역자를 위한 우리말 공부
갈등하는 번역
문장 기술
읽지도 않은 책 목록을 올리는게 이상한 기분이 들긴 하지만 혹시나 해서 넣었다. 연말 휴가 기간 동안에 마련할 수 있는 책은 찾아서 읽어볼 생각이다.
기대보다는 걱정이 더 많이 되는 것이 사실이다. 트위터에서 번역 질이 안좋은 책은 어떤 혹독한 대우를 받고 사는지 자주 봐서 이 책으로 불로장생을 실현하게 될까 걱정이 된다. 더군다나 책에 역자로 내 이름이 올라간다고 해서 나만의 책인 것이 아니라 교정부터 디자인, 출력 등 내가 알기도 모르기도 하는 수많은 손이 함께 한다는 생각이 문득 문득 들어 밥이 넘어가지 않을 때가 있다. 이미 원고가 내 손을 떠나 어떻게 할 수 없는 상황에서도 그런 기분이 든다. 책을 실물로 보면 좀 홀가분해질지, 그때가 되어봐야 알 것 같다.
그리고 한편 뿌듯했던 부분은 블로그에 계속 올린 번역을 보고 연락을 받았다는 점이다. 기술적인 내용이나 유익한 글은 번역하며 꼼꼼하게 보고 더 오래 기억하고 싶기도 했고 같이 읽고 싶다는 생각에 계속 번역을 올렸었다. 이런 번역이 일종의 포트폴리오가 되리라고는 생각을 해보진 못했다. 앞으로 어떻게 될 지 잘 모르겠지만 그래도 예전보다는 조금 더 꼼꼼하게 글을 올리게 될 것 같다.
먼 길을 가도 그 시작은 첫 발을 내딛는 일에서, 구렁이 담 넘어가듯 모던 PHP 넘어가기 시리즈.
Published on October 12, 2016
흔히 모던 PHP라고 말하는 현대적인 PHP 개발 방식에 대해 많은 이야기가 있다. 새 방식을 사용하면 협의된 명세를 통해 코드 재사용성을 높이고 패키지를 통해 코드 간 의존성을 낮출 수 있는 등 다른 프로그래밍 언어에서 사용 가능했던 좋은 기능을 PHP에서도 활용할 수 있게 된 것이다. 이 방식은 과거 PHP 환경에 비해 확실히 개선되었다. 하지만 아무리 좋은 개발 방식이라 해도 현장에서 쉽게 도입하기 어렵다. 코드 기반이 너무 커서 일괄 전환이 어렵거나, 이전 환경에 종속적인 경우(mysql_* 함수를 여전히 사용), 새로운 개발 방식을 적용하기 위한 재교육 비용이 너무 크고, 신규 프로젝트와 구 프로젝트가 공존하는 동안 전환 비용이 발생할 수 있다는 점이 걸림돌이 된다. 이런 이유로 사내 정책 상 예전 환경을 계속 사용하기로 결정할 수도 있고, 개개인의 선택에 따라 계속 이전 버전을 사용하는 경우도 있을 것이다. 그 결과, 좋은 개발 방식임을 이미 알고 있지만 마치 다른 나라 이야기처럼 느끼는 사람도 많다.
A: 팀장님 모던 PHP 도입합시다 +_+
B:
지금 다니고 있는 회사에서도 모든 코드를 일괄적으로 모던 PHP로 이전할 수 없었다. 가장 큰 문제는 코드란 혼자서만 작성하는 것이 아니며 다른 개발자와의 협업도 고려해야 하기 때문에 구성원 간의 협의가 필요하다. 그래서 일괄적인 도입보다는 점진적으로 코드는 개선해 가면서 새 개발 방식에 천천히 적응하는 방법은 없는지 고민하게 되었다. 작은 코드부터 시작해서 먼저 도입할 수 있는 부분부터 차근차근 도입하기 시작했다. 아직 회사에서 사용하는 대다수의 프레임워크와 CMS가 이전 방식을 기반으로 하고 있기 때문에 100% 모던 PHP를 사용하는 것은 아직 멀었지만, 팀 내에서 작은 크기의 코드인데도 새 방식의 장점과 필요성을 설득하기에 충분한 역할을 할 수 있었다.
레거시 PHP 코드에서 모던 PHP 코드로
이전 PHP 코드를 사용하면서도 현대적인 PHP를 도입하기 위해 고민하고 있다면 도움이 되지 않을까 하는 생각으로 이렇게 정리하게 되었다. 이 글에서 다루는 내용은 내가 소속된 회사에서도 현재 진행형이다. 즉, 이 글을 따라서 해야만 정답인 것은 아니다. 프로젝트의 수 만큼 다양한 경우의 수가 존재하기 때문에 하나의 방법만 고집할 수는 없다. 이 글이 그 정답을 찾기 위한 과정에서 도움이 되었으면 좋겠다.
먼 길을 가도 그 시작은 첫 발을 내딛는 일에서 시작한다. 이전의 코드 기반에서 여전히 작업하고 있고, 그 코드 양이 너무 많다 하더라도 점진적으로 코드를 개선할 수 있는 방법이 있다. 여기에서 다룰 내용은 모던 PHP를 도입하기 위해 회사에서 작업했던 작은 부분을 정리한 것이다. 코드를 개선하면서 전혀 지식이 없는 구성원도 자연스레 학습할 수 있도록 학습 곡선을 완만하게 만들기 위해 노력했던 부분도 함께 정리해보려고 한다. 가장 먼저 뷰를 분리하는 것에 대해 다뤄보려고 한다.
뷰 분리하기
코드를 분리해서 작성하는 과정은 중요하다. 각 코드가 서로에게 너무 의존적이거나 한 쪽이 다른 한 쪽을 너무 잘 아는 경우에는 코드 재사용도 어렵고 제대로 구동되는지 확인하기도 어렵다. PHP는 언어적인 특징 때문인지 몰라도 뷰 부분이 특히 심하게 붙어있는 모습을 자주 발견할 수 있다.
MVC 패턴을 사용하는 PHP 프레임워크 또는 플랫폼을 사용하는 프로젝트라면 별도로 뷰를 분리하는 노력 없이도 자연스럽게 로직과 뷰를 구분해서 작성할 수 있다. 하지만 여전히 많은 PHP 프로젝트는 echo로 HTML 문자열을 직접 출력하거나 include를 사용해서 별도의 파일을 불러오는 방식으로 개발되어 있다. 예를 먼저 확인해 보자.
이 코드를 보면 앞서 방식보다는 뷰가 분리된 것처럼 보인다. 하지만 이 코드는 뷰를 분리했다기 보다는 두개의 PHP 파일로 나눠서 작성하는 방식에 가깝다.
여기서 살펴본 두 경우는 이전에 작성된 코드라면 쉽게 찾을 수 있는 방식이다. 빠르고 간편하게 작성할 수 있을지 몰라도 재사용성이 높지 않고 관리가 쉽지 않다. 그나마 두 번째 방식은 분리되어 있지만 그렇다고 편리하다고는 할 수 없는 구석이 많다. 왜 이렇게 작성된 코드는 불편한 것일까?
전자의 경우는 외부의 함수를 그대로 사용하고 있어서 뷰의 의존도가 높다. 함수의 반환 값이나 사용 방식이 달라지면 뷰에서 해당 함수를 사용한 모든 위치를 찾아서 변경해야 할 것이다. 그리고 이렇게 생성된 html을 다른 곳에서 다시 사용하기는 쉽지 않다. 이 파일을 다른 파일에서 불러오게 되면 파일 내에 포함되어 있는 모든 기능을 호출하게 된다. 이 파일을 다시 사용하더라도 작성했을 당시의 의도를 바꾸기 어렵다.
그래도 후자의 경우는 뷰가 분리되어 있어서 뷰를 다시 사용하는 것은 가능하게 느껴진다. 하지만 뷰에서 전역 변수에 접근하는 방식으로 데이터에 접근하고 있다. 이런 상황에서는 뷰에서 어떤 변수를 사용하고 있는지 뷰 코드를 들여다보기 전까지는 알기 어렵다. 이런 방식으로 뷰를 재사용하게 되면 해당 파일을 include 하기 전에 어떤 변수를 php 내부에서 사용하고 있는지 살펴본 후, 모두 전역 변수로 선언한 다음 include를 수행해야 한다.
결과를 예측할 수 없는 코드
PHP에서는 결과를 출력하는데 수고가 전혀 필요 없다. 위 코드에서 보는 것처럼 <?php ?>로 처리되지 않은 부분과 echo를 사용해서 출력한 부분은 바로 화면에 노출되기 때문이다. 이 특징은 짧은 코드를 작성할 때 큰 고민 없이 빠르게 작성할 수 있도록 하지만 조금이라도 규모가 커지기 시작하면 관리를 어렵게 만든다.
앞에서 확인한 예제처럼 작성한 PHP 코드가 점점 관리하기 어렵게 변하는 이유는 바로 출력되는 결과를 예측하는 것이 불가능하다는 점 에서 기인한다. (물론 e2e 테스트를 수행할 수 있지만 이런 코드를 작성하는 곳에서 e2e 테스트를 사용한다면 특수한 경우다.) 두 파일에서 출력하는 내용은 변수로 받은 후 출력 여부를 결정하는 흐름이 존재하지 않는다. 전자는 데이터를 직접 가져와서 바로 출력하고 있고 후자는 가져올 데이터를 전역 변수를 통해 접근하고 있다. 개발자의 의도에 따라서 통제되는 방식이라고 하기 어렵다. 오히려 물감을 가져와서 종이 위에 어떻게 뿌려지는지 쏟아놓고 보는 방식에 가깝다. 이전 코드를 사용하는 PHP는 대부분 일단 코드를 쏟은 후에 눈과 손으로 직접 확인하는 경우가 많다. 이는 코드가 적을 경우에 문제 없지만 커지면 그만큼 번거로운 일이 된다. 결국에는 통제가 안되는 코드를 수정하는 일은 꺼림칙하고 두려운 작업이 되고 만다.
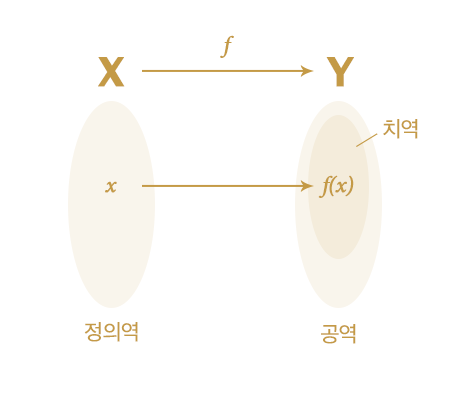
함수에 대해 생각해보자. 프로그래밍을 하게 되면 필연적으로 함수를 작성하게 된다. 함수는 인자로 값을 입력하고, 가공한 후에 결과를 반환한다. 대부분의 함수는 특수한 용도가 아닌 이상에는 같은 값을 넣었을 때 항상 같은 결과를 반환한다. 수학에서는 함수에 인자로 전달할 수 있는 값의 집합을 정의역으로, 결과로 받을 수 있는 값의 집합을 치역으로 정의한다. 프로그래밍에서의 함수도 동일하게 입력으로 사용할 수 있는 집합과 그 입력으로 출력되는 결과 값 집합이 존재한다. 즉, 입력의 범위를 명확히 알면 출력되는 결과물도 명확하게 알 수 있다는 뜻이다.
수학에서의 함수
뷰를 입력과 출력이 존재하는 함수라는 관점에서 생각해보자. 위에서 작성했던 코드를 다시 보면 $session과 $users를 입력받고 html로 변환한 값을 반환하는 함수로 볼 수 있다. 함수 형태로 뷰를 사용한다면 뷰에서 사용할 변수를 인자로 사용할 수 있어서 입력을 명확하게 통제할 수 있다. 앞서 본 함수의 특징처럼 이 뷰 함수도 입력에 따라 그 결과인 html을 예측할 수 있게 된다. 다시 말해, 그동안 사용한 뷰를 함수처럼 바꾼다면 입력과 출력의 범위를 명확하게 파악할 수 있게 되는 것이다.
php의 뷰 함수
뷰 함수로 전환하기
간단하게 뷰를 불러오는 함수를 구현해보자. 파일을 불러오더라도 출력하는 결과를 예측할 수 있도록 만들 수 있다. 다음처럼 include로 불러온 내용을 결과로 반환하도록 작성한다.
<?phpfunctionview($template) {
if (is_file($template)) {
ob_start();
include$template;
returnob_get_clean();
}
returnnewException("Template not found");
}
?>
출력 버퍼를 제어하는 함수 ob_start(), ob_get_clean()을 사용해서 불러온 결과를 반환했다. 이 함수를 사용해서 외부 파일을 불러와도 바로 출력되지 않고 변수로 받은 후 출력할 수 있게 되었다.
여기서 사용한 뷰 함수는 간단한 예시로, 뷰를 불러오는 환경을 보여주기 위한 예제에 불과하다. 실제로 사용하게 될 때는 레이아웃 내 다양한 계층과 구성 요소를 처리해야 하는 경우가 많다. 이럴 때는 이 함수로는 부족하며 이런 함수 대신 다양한 환경을 고려해서 개발된 템플릿 패키지를 적용하는 게 바람직하다.
템플릿 패키지 사용하기
다양한 PHP 프레임워크는 각자 개성있고 많은 기능을 가진 템플릿 엔진을 사용하고 있다. Laravel은 Blade, Symfony는 Twig을 채택하고 있다. 모두 좋은 템플릿 엔진이고, PHP와는 다르게 독자적인 문법을 채택해서 작성하는 파일이 뷰의 역할만 할 수 있도록 PHP 전체의 기능을 제한하고 최대한 뷰 역할을 수행하도록 적절한 문법을 제공한다. 이런 템플릿 엔진을 사용할 수 있는 환경이라면 편리하고 가독성 높은 템플릿 문법을 사용할 수 있다.
프레임워크를 사용하지 않는 환경이라면 이런 템플릿 엔진이 학습 곡선을 더한다는 인상을 받을 수 있으며 같이 유지보수 하는 사람에게 부담을 줄 수도 있다. 이런 경우에는 PHP를 템플릿으로 사용하는 템플릿 엔진을 선택할 수 있다. 사용하는 템플릿이 여전히 PHP 파일과 같은 문법을 사용하면서도 앞에서 작성해본 뷰 함수와 같이 통제된 환경을 제공할 수 있는 패키지가 있다. 여기서는 Plates를 사용해서 앞에서 작성한 코드를 수정해볼 것이다.
먼저 Plates를 composer로 설치한다.
$ composer require league/plates
그리고 php 앞에서 autoload.php를 불러와 내려받은 plates를 사용할 수 있도록 한다.
<?php// dashboard.phprequire_once('vendor/autoload.php');
require_once('lib.php');
// templates을 기본 경로와 함께 초기화$templates = newLeague\Plates\Engine('templates');
$session = get_session();
if ( $session->is_logged_in() ) {
$user = get_user($session->get_current_user_id());
} else {
$user = null;
}
// 앞서 view 함수처럼 사용echo$templates->render('dashboard', [ 'user' => $user ]);
Plates는 레이아웃, 중첩, 내부 함수 사용이나 템플릿 상속 등 편리한 기능을 제공한다. 자세한 내용은 Plates의 문서를 확인한다.
정리
지금까지 뷰를 분리하는 과정을 간단하게 살펴봤다. MVC 프레임워크처럼 구조가 잘 잡힌 코드를 사용하는 것이 가장 바람직하겠지만, 점진적으로 코드를 개선하려면 여기서 살펴본 방식대로 뷰를 먼저 분리하는 것부터 작게 시작할 수 있다.
뷰 함수 또는 템플릿 엔진을 사용해서 외부 환경의 영향을 받지 않는 독립적인 뷰를 만들 수 있다. 뷰가 결과로 반환되기 때문에 출력 범위를 예측하고 테스트 할 수 있게 된다. 또한 뷰에 집어넣는 값을 통제할 수 있다. 전역 변수 접근을 차단하는 것으로 외부 요인의 영향을 최대한 줄일 수 있다.
그리고 새로운 내용을 배우거나 도입하는데 거리낌이 있는 경우라도 타 템플릿 엔진과 달리 Plates 같은 템플릿 엔진은 PHP 로직을 그대로 사용할 수 있기 때문에 상대적으로 자연스럽게 도입할 수 있다.
이상적인 상황을 가정해보면 이 패키지를 composer를 사용해서 설치하는 것으로 새로운 개발 흐름에 조금씩 관심을 갖게 만들 수 있고 새로운 패키지를 도입하는 것에 대해 좋은 인상을 남길 수 있다. 또한 추후에 MVC 프레임워크를 도입해도 뷰를 분리해서 작성하는 방식에 자연스럽게 녹아들 수 있을 것이다.
함수의 호출 결과를 캐시로 만드는 @memoize 데코레이터 설명. 캐시 상황에서 문제 해결하기, 번역.
Published on September 26, 2016
파이썬에서 데코레이터를 정말 자주 사용하고 있지만 다양한 용례는 접해보지 못했었다. Ned Batchelder의 글 Isolated @memoize은 @memoize 데코레이터에 대한 이야기인데 같이 곁들여진 설명과 각 링크가 유익해서 번역했다. 파이썬 데코레이터 모음 위키 페이지도 살펴보면 좋겠다.
파이썬 @memoize 고립된 환경에서 사용하기
실행 비용이 비싼 함수를 호출한다고 생각해보자. 동일한 입력을 했을 때 동일한 결과를 반환하는 함수인 경우에는 사람들 대부분은 @memoize 데코레이터를 사용하는 것을 선호한다. 이 데코레이터는 이전에 실행한 적이 있는 경우에는 동일한 결과를 빠르게 내놓을 수 있도록 캐시해둔다. 다음은 @memoize 구현 모음을 차용해서 만든 간단한 코드다.
defmemoize(func):
cache = {}
defmemoizer(*args, **kwargs):
key = str(args) + str(kwargs)
if key notin cache:
cache[key] = func(*args, **kwargs)
return cache[key]
return memoizer
@memoizedefexpensive_fn(a, b):
return a + b # 물론 이 함수는 그렇게 비싼 연산이 아니다!
이 코드는 원하는 동작을 제대로 수행하는 좋은 코드다. expresive_fn 함수를 동일한 인자로 반복해서 호출하면 실제로 함수를 호출하지 않고 캐시된 값을 사용할 수 있다.
하지만 여기에는 잠재적인 위험이 있다. 캐시 딕셔너리가 전역이라는 점이다. 물론 이 말을 문자 그대로 전역이라고 생각하는 잘못을 범하지 말자. global 키워드를 사용하지 않았고 모듈 단위의 변수인 것도 아니다. 하지만 이 딕셔너리는 프로세스 전체에서 expensive_fn를 대상으로 오직 하나의 캐시 딕셔너리를 갖고 있기 때문에 이 관점에서는 전역 변수라고 말할 수 있을 것이다.
전역은 잘 짜여진 테스트를 방해할 수 있다. 자동화된 테스트에서 가장 이상적인 동작 방식은 각 테스트가 서로 영향을 미치지 않도록 고립된 형태로 테스트를 수행하는 것이다. test1에서 어떤 일이 일어나든지 test99에는 영향이 없어야 한다. 하지만 여기서 test1부터 test99까지 expensive_fn을 (1, 2) 인자를 사용해서 호출했다면 test1은 함수를 호출하지만 test99는 캐시에 저장된 값을 사용한다. 더 나쁜 부분은 전체 테스트를 호출하면 test99는 캐시에 저장된 값을 사용하게 될 것인 반면 test99만 실행하면 함수를 실제로 실행하게 된다는 점이다.
만약 expensive_fn이 정말로 부작용 없는 순수 함수라면 이런 특징이 문제가 되지 않을 것이다. 하지만 때로는 문제가 되는 경우도 있다.
내가 관리하게 된 프로젝트 중에 고정된 데이터를 가져오기 위해 @memoize를 사용하는 웹사이트가 있었다. 자료를 가져올 때 단 한 번만 가져왔기 때문에 @memoize는 적절했고 프로그램을 사용하는데 전혀 문제가 되질 않았다. 테스트는 Betamax를 사용해서 네트워크 접근을 모조로 만들었다.
Betamax는 대단한 라이브러리다. 각 테스트 케이스를 구동할 때 각 테스트에서의 네트워크 접근을 확인한 후, “카세트”에 요청과 반환을 JSON 양식으로 저장한다. 다시 테스트를 수행하면 카세트에 저장되어 있는 정보를 사용해서 네트워크 접근을 모조해서 처리해준다.
문제는 test1의 카세트에서 캐시로 저장될 자원을 네트워크로 요청하게 되고 test99는 @memoize로 인해 네트워크를 통해 데이터를 요청할 필요가 없어졌기 때문에 test99의 카세트가 제대로 생성이 되지 않는다. 이제 테스트를 test99만 구동했을 때 카세트에 저장된 정보가 없기 때문에 테스트가 실패하게 된다. test1과 test99는 각각 고립되서 실행된다고 볼 수 없다. 저장된 캐시를 통해서 전역적으로 값을 공유하기 때문이다.
내 해결책은 @memoize를 사용했을 때 테스트 사이에 캐시 내용을 지우는 방식이다. 이 코드를 직접 작성하기 보다는 functools에 포함되어 있는 lru_cache 데코레이터를 사용할 수 있다. (여전히 2.7 버전의 파이썬을 사용하고 있다면 functools32을 찾아보자.) 이 데코레이터는 전역 캐시의 모든 값을 지울 수 있는 .cache_clear 함수를 제공한다. 이 함수는 각 데코레이터를 사용한 함수에 있기 때문에 사용한 함수를 목록으로 갖고 있어야 한다.
import functools
# memoize를 사용한 함수 목록을 저장. 그런 후# `clear_memoized_values`로 일괄 비우기를 수행.
_memoized_functions = []
defmemoize(func):
"""함수를 호출해서 반환한 값을 캐시로 저장함"""
func = functools.lru_cache()(func)
_memoized_functions.append(func)
return func
defclear_memoized_values():
"""@memoize에 저장된 모든 값을 비워서 각 테스트가 고립된 환경으로 동작할 수 있도록 함"""for func in _memoized_functions:
func.cache_clear()
이제 각 테스트 전에 캐시를 비우기 위해 py.test의 픽스쳐에서, 또는 테스트 케이스의 setUp() 메서드에서 clear_memoized_values() 함수를 사용할 수 있다.
# py.test를 사용하는 경우@pytest.fixture(autouse=True)defreset_all_memoized_functions():
"""@memoize에 캐시로 저장된 값을 매 테스트 전에 비움"""
clear_memoized_values()
# unittest를 사용하는 경우classMyTestCaseBase(unittest.TestCase):
defsetUp(self):
super().setUp()
clear_memoized_values()
사실 @memoize를 사용하는 다양한 이유를 보여주는 것이 더 나을지도 모른다. 순수 함수는 모든 테스트에서 캐시를 사용해서 같은 값을 반환해도 문제가 없을 것이다. 연산이 필요한 경우라면 누가 이런 문제를 신경 쓸까? 하지만 다른 경우에서는 확실히 고립된 환경을 만들어서 사용해야 한다. @memoize는 마술이 아니다. 이 코드가 어떤 일을 하는지, 어떤 상황에서 더 제어가 필요한지 잘 알아야 한다.
파이썬을 처음 공부할 때 리스트와 튜플에 대해 비슷한 의문을 가진 적이 있었다. 이 둘을 비교하고 설명하는 Ned Batchelder의 Lists vs. Tuples 글을 번역했다. 특별한 내용은 아니지만 기술적인 차이와 문화적 차이로 구분해서 접근하는 방식이 독특하게 느껴진다.
Python에 입문하는 사람들이 흔하게 하는 질문이 있다. 리스트(list)와 튜플(tuple)의 차이는 무엇인가?
이 질문의 답변은 이렇다. 이 두 타입은 각각 상호작용에 있어 두 가지 다른 차이점이 존재한다. 바로 기술적인 차이와 문화적인 차이다.
먼저 두 타입의 공통점을 확인하자. 리스트와 튜플은 둘 다 컨테이너로 일련의 객체를 저장하는데 사용한다.
둘 다 타입과 상관 없이 일련의 요소(element)를 갖을 수 있다. 두 타입 모두 요소의 순서를 관리한다. (세트(set)나 딕셔너리(dict)와 다르게 말이다.)
이제 차이점을 보자. 리스트와 튜플의 기술적 차이점은 불변성에 있다. 리스트는 가변적(mutable, 변경 가능)이며 튜플은 불변적(immutable, 변경 불가)이다. 이 특징이 파이썬 언어에서 둘을 구분하는 유일한 차이점이다.
>>> my_list[1] = "two">>> my_list
[1, 'two', 3]
>>> my_tuple[1] = "two"
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'tuple'object does not support item assignment
이 특징은 리스트와 튜플을 구분하는 유일한 기술적 차이점이지만 이 특징이 나타나는 부분은 여럿 존재한다. 예를 들면 리스트에는 .append() 메소드를 사용해서 새로운 요소를 추가할 수 있지만 튜플은 불가능하다.
>>> my_list.append("four")
>>> my_list
[1, 'two', 3, 'four']
>>> my_tuple.append("four")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'tuple'object has no attribute 'append'
튜플은 .append() 메소드가 필요하지 않다. 튜플은 수정할 수 없기 때문이다.
문화적인 차이점을 살펴보자. 리스트와 튜플을 어떻게 사용하는지에 따른 차이점이 있다. 리스트는 단일 종류의 요소를 갖고 있고 그 일련의 요소가 몇 개나 들어 있는지 명확하지 않은 경우에 주로 사용한다. 튜플은 들어 있는 요소의 수를 사전에 정확히 알고 있을 경우에 사용한다. 동일한 요소가 들어있는 리스트와 달리 튜플에서는 각 요소의 위치가 큰 의미를 갖고 있기 때문이다.
디렉토리 내에 있는 파일 중 *.py로 끝나는 파일을 찾는 함수를 작성한다고 가정해보자. 이 함수를 사용했을 때는 파일을 몇 개나 찾게 될 지 알 수 없다. 그리고 동일한 규칙으로 찾은 파일이기 때문에 항목 하나 하나가 의미상 동일하다. 그러므로 이 함수는 리스트를 반환할 것이다.
(지금은 클래스를 사용하는 것에 대해서 이야기하지 않을 것이다.) 이 튜플에서 첫 요소는 식별번호, 두 번째는 도시… 순으로 작성했다. 튜플에서의 위치가 담긴 내용이 어떤 정보인지를 나타낸다.
C 언어에서 이 문화적 차이를 대입해보면 목록은 배열(array) 같고 튜플은 구조체(struct)와 비슷할 것이다.
파이썬은 네임드튜플(namedtuple)을 제공하는데 이 네임드튜플을 사용하면 튜플에서 각 위치의 의미를 명시적으로 작성할 수 있다.
>>> from collections import namedtuple
>>> Station = namedtuple("Station", "id, city, state, lat, long")
>>> denver = Station(44, "Denver", "CO", 40, 105)
>>> denver
Station(id=44, city='Denver', state='CO', lat=40, long=105)
>>> denver.city
'Denver'>>> denver[1]
'Denver'
튜플과 리스트의 문화적 차이를 영악하게 정리한다면 튜플은 네임드튜플에서 이름이 없는 것이라고 할 수 있다.
기술적 차이점과 문화적 차이점을 연계해서 생각하기란 쉽지 않은데 종종 이 차이점이 이상할 때가 있기 때문이다. 왜 단일 종류의 일련 데이터는 가변적이고 여러 종류의 일련 데이터는 불변이어야 하는 것일까? 예를 들면 앞에서 저장했던 기상관측소의 데이터는 수정할 수 없다. 네임드 튜플은 튜플이고 튜플은 불변이기 때문이다.
>>> denver.lat = 39.7392
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: can't set attribute
때때로 기술적인 고려가 문화적 고려를 덮어쓰는 경우가 있다. 리스트를 딕셔너리에서 키로 사용할 수 없다. 불변 값만 해시를 만들 수 있기 때문에 키에 불변 값만 사용 가능하다. 대신 리스트를 키로 사용하고 싶다면 다음 예처럼 리스트를 튜플로 변경했을 때 사용할 수 있다.
>>> d = {}
>>> nums = [1, 2, 3]
>>> d[nums] = "hello"
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: unhashable type: 'list'>>> d[tuple(nums)] = "hello">>> d
{(1, 2, 3): 'hello'}
기술과 문화가 충돌하는 또 다른 예가 있다. 파이썬에서도 리스트가 더 적합한 상황에서 튜플을 사용하는 경우가 있다. *args를 함수에서 정의했을 때, args로 전달되는 인자는 튜플을 사용한다. 함수를 호출할 때 사용한 인자의 순서가 크게 중요하지 않더라도 말이다. 튜플은 불변이고 전달된 값은 변경할 수 없기 때문에 이렇게 구현되었다고 말할 수 있겠지만 그건 문화적 차이보다 기술적 차이에 더 가치를 두고 설명하는 방식이라 볼 수 있다.
물론 *args에서 위치는 매우 큰 의미를 갖는다. 매개변수는 그 위치에 따라 의미가 크게 달라지기 때문이다. 하지만 함수는 *args를 전달 받고 다른 함수에 전달해준다고만 봤을 때 *args는 단순히 인자 목록이고 각 인자는 별 다른 의미적 차이가 없다고 할 수 있다. 그리고 각 함수에서 함수로 이동할 때마다 그 목록의 길이는 가변적인 것으로 볼 수 있다.
파이썬이 여기서 튜플을 사용하는 이유는 리스트에 비해서 조금 더 공간 효율적이기 때문이다. 리스트는 요소를 추가하는 동작을 빠르게 수행할 수 있도록 더 많은 공간을 저장해둔다. 이 특징은 파이썬의 실용주의적 측면을 나타낸다. 이런 상황처럼 *args를 두고 리스트인지 튜플인지 언급하기 어려운 애매할 때는 그냥 상황을 쉽게 설명할 수 있도록 자료 구조(data structure)라는 표현을 쓰면 될 것이다.
대부분의 경우에 리스트를 사용할지, 튜플을 사용할지는 문화적 차이에 기반해서 선택하게 될 것이다. 어떤 의미의 데이터인지 생각해보자. 만약 프로그램이 실제로 다루는 자료가 다른 길이의 데이터를 갖는다면 분명 리스트를 써야 할 것이다. 작성한 코드에서 세 번째 요소에 의미가 있는 경우라면 분명 튜플을 사용해야 할 상황이다.
반면 함수형 프로그래밍에서는 코드를 어렵게 만들 수 있는 부작용을 피하기 위해서 불변 데이터 구조를 사용하라고 강조한다. 만약 함수형 프로그래밍의 팬이라면 튜플이 제공하는 불변성 때문에라도 분명 튜플을 좋아하게 될 것이다.
자, 다시 질문해보자. 튜플을 써야 할까, 리스트를 사용해야 할까? 이 질문의 답변은 항상 간단하지 않다.
반 년 전에 Orvibo S20이라는 스마트 소켓을 구입했다. 스마트 소켓은 스위치를 제어할 수 있도록 Wifi 모듈이 내장되어 있다. 스마트폰 앱을 사용해서 이 소켓의 전원을 올렸다 내렸다 할 수 있는데 집에 있는 거실 스탠드와 안방 스탠드에 연결해서 사용하고 있었다. Orvibo에서는 WiMo라는 앱을 제공하는데 앱이 상당히 부실하고 연결이 오락가락하는 문제점이 있었다. 또한 같은 wifi 네트워크 내에서만 동작하기 때문에 집을 나서면 불을 켜고 나왔는지 확인할 방법이 없었다. 이렇게 생각보다 활용도가 많이 떨어져서 제대로 쓰지 않고 방치하고 있었다.
어느 날 거실에서 방을 들어가는데 불을 끄고 스마트폰을 손전등처럼 쓰는 내 모습을 보고는 왜 사놓고 제대로 못쓰고 있나 생각이 확 들었다. 그래서 간단하게라도 만들어보기로 했다.
Orvibo에서는 딱히 개발을 위한 API를 공개하지 않았지만 S20 인터페이스를 리버싱해서 어떤 방식으로 제어할 수 있는지 분석한 사람들이 오픈소스 라이브러리로 내놓기 시작했다. 마침 집에서 방치하고 있던 라즈베리 파이가 있었고 최근 부지런히 사용하고 있는 텔레그램과 연동해서 아주 간단하게 외부에서 제어 가능한 환경을 만들 수 있었다.
사용한 라이브러리
텔레그램 봇을 만들 수 있는 파이썬 패키지는 엄청 많다. python-telegram-bot같은 멋진 라이브러리도 있지만 간단하게 데코레이터 문법으로 작성할 수 있는 pyTelegramBotAPI을 골랐다. 이 패키지는 간단한 기능만 제공하고 있어서 텔레그램의 고급 기능을 사용하려면 다른 패키지를 고르는 것이 낫다.
S20을 제어하는 패키지는 happyleavesaoc/python-orvibo를 사용했다. S20 자체에도 타이머나 추가적인 설정이 가능하지만 이 패키지는 그 기능을 지원하지 않는다. 그래도 자체 기능보다는 프로그램 쪽에서 제어하는게 편해서 제대로 켜고 끌 수만 있기만 하면 되서 이 패키지를 사용하게 되었다.
라우터 설정
라우터에서 설정할 부분은 크게 없었다. 텔레그램 봇은 네트워크 내에서 polling 해오는 방식이라서 별도로 포트를 포워딩해 외부 접근을 허용하거나 할 필요가 전혀 없었다. 대신 편의를 위해서 S20의 IP를 수동으로 할당해 내부에서 고정 IP로 접근할 수 있도록 변경했다.
봇에 문제가 생겨도 다시 실행되도록 Supervisor를 사용했다. pip을 사용해서 설치하려 했는데 python3 환경에선 사용하지 못한다고 나왔다. 대신 systemd를 추천 받아서 설치하려는데 라즈비안엔 없어서 고민했는데 apt-get에 Supervisor가 올라와 있어서 쉽게 해결할 수 있었다.
$ sudo apt-get install supervisor
supervisord.conf를 간단하게 작성하고 실행했다. 전체 경로로 지정하고 싶지 않다면 PATH를 추가해도 된다.
S20이 종종 연결이 끊어지는 문제가 있는데 S20으로부터 응답이 없으면 코드에 별도의 에러 핸들링이 없어서 봇이 재시작되었다. 이 경우에는 시간이 지나면 알아서 S20이 다시 붙거나 아니면 S20을 뽑았다 다시 끼워야 한다. 연결에 실패한 것이라도 확인할 수 있도록 코드를 조금 수정했다.
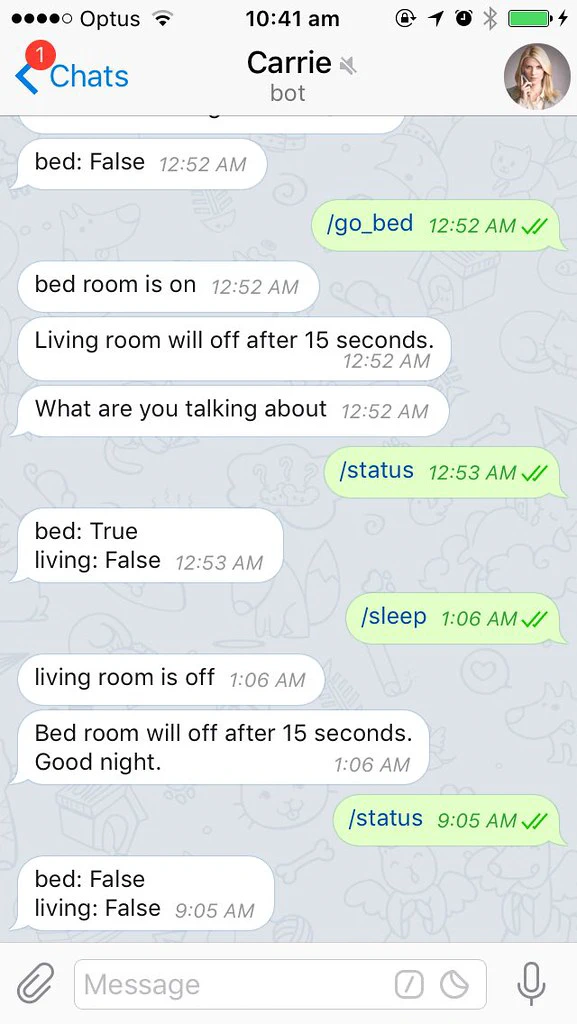
실제로 사용해보니 생각보다 조작을 많이 해야해서 타이머를 이용해 일종의 오토메이션 명령어를 추가했다.
import time
@bot.message_handler(commands=["go_to_bed"])defgo_to_bed(message):
bed_room_on(message)
bot.send_message(message.chat.id, "Living room light will turn off 15 secs after.")
time.sleep(15)
living_room_off(message)
얼마 전 iOS 10 업데이트를 하면서 Home 앱이 기본적으로 들어왔는데 애플의 HomeKit과 연동이 가능하면 사용할 수 있다고 한다. 이 프로토콜을 사용할 수 있도록 구현한 패키지가 nodejs에 존재하는데 HAP-NodeJS와 homebridge다. 이 도구와 연동하면 Siri를 이용해서 켜고 끌 수 있다는 장점이 있어서 여기서 작성한 코드를 조만간 연동 가능하게 만들어볼 생각이다.
각 장비에서 직접 API를 제공하거나 API를 사용해서 제어할 수 있는 방식에서 마이크로 서비스 아키텍처의 향기가 난다. 대부분의 홈 오토메이션 장비가 게이트웨이를 필요로 한다. 이 글에서는 라즈베리 파이를 썼고 애플의 HomeKit에서는 애플TV가 그런 역할을 한다. 마치 MSA의 API Gateway와 같은 방식으로 말이다. 앞으로 어떤 도구들이 재미있는 API를 들고 나올지 기대된다.
파이썬의 의존성 관리 양대산맥, setup.py vs requirements.txt 용도와 차이점 살펴보기, 번역
Published on September 13, 2016
파이썬을 사용하다보면 setup.py와 requirements.txt를 필연적으로 마주하게 된다. 처음 봤을 때는 이 둘의 용도가 비슷하게 느껴져서 마치 둘 중 하나를 골라야 하는지, 어떤 용도로 무엇을 써야 하는지 고민하게 된다. 같은 내용을 이상한모임 슬랙에서 물어봤었는데 Donald Stufft의 글 setup.py vs requirements.txt를 raccoonyy님이 소개해줬다. 이 두 도구를 사용하는 방식을 명확하게 잘 설명하는 글이라서 허락 받고 번역으로 옮겼다.
setup.py와 requirements.txt의 차이점과 사용 방법
setup.py와 requirements.txt의 역할에 대한 오해가 많다. 대부분의 사람들은 이 두 파일이 중복된 정보를 제공하고 있다고 생각한다. 심지어 이 “중복”을 다루기 위한 도구를 만들기까지 했다.
파이썬 라이브러리
이 글에서 이야기하는 파이썬 라이브러리는 타인이 사용할 수 있도록 개발하고 릴리스하는 코드를 의미한다. 다른 사람들이 만든 수많은 라이브러리는 PyPI에서 찾을 수 있을 것이다. 각각의 라이브러리가 제공될 때 문제 없이 배포될 수 있도록 패키지는 일련의 메타데이터를 포함하게 된다. 이 메타데이터에는 명칭, 버전, 의존성 등을 적게 된다. 라이브러리에 메타데이터를 작성할 수 있도록 다음과 같은 형식을 setup.py 파일에서 사용할 수 있다.
이 방식은 매우 단순해서 필요한 메타 데이터를 정의하기에 부족하지 않다. 하지만 이 명세에서는 이 의존성을 어디에서 가져와 해결해야 하는지에 대해서는 적혀있지 않다. 단순히 “requests”, “bcrypt”라고만 적혀있고 이 의존성이 위치하고 있는 URL도, 파일 경로도 존재하지 않는다. 어디서 의존 라이브러리를 가져와야 하는지 분명하지 않지만 이 특징은 매우 중요한 것이다. 이 특징을 지칭하는 특별한 용어가 있는 것은 아니지만 이 특징을 일종의 “추상 의존성(abstract dependencies)”라고 이야기할 수 있다. 이 의존성에는 의존 라이브러리의 명칭만 사용할 수 있고 선택적으로 버전 지정도 가능하다. 의존성 라이브러리를 사용하는 방식이 덕 타이핑(duck typing)과 같은 접근 방식을 사용한다고 생각해보자. 이 맥락에서 의존성을 바라보면 특정 라이브러리인 “requests”가 필요한 것이 아니라 “requests”처럼 보이는 라이브러리만 있으면 된다는 뜻이다.
파이썬 어플리케이션
여기서 이야기하는 파이썬 어플리케이션은 일반적으로 서버에 배포(deploy)하게 되는 부분을 뜻한다. 이 코드는 PyPI에 존재할 수도 있고 존재하지 않을 수도 있다. 하지만 어플리케이션에서는 재사용을 위해 작성한 부분은 라이브러리에 비해 그리 많지 않을 것이다. PyPI에 존재하는 어플리케이션은 일반적으로 배포를 위한 특정 설정 파일이 필요하다. 여기서는 “배포라는 측면에서의” 파이썬 어플리케이션을 중심으로 두고 살펴보려고 한다.
어플리케이션은 일반적으로 의존성 라이브러리에 종속되어 있으며 대부분은 복잡하게 많은 의존성을 갖고 있는 경우가 많다. 과거에는 이 어플리케이션이 어떤 라이브러리에 의존성이 있는지 확인할 수 없었다. 이렇게 배포(deploy)되는 특정 인스턴스는 라이브러리와 다르게 명칭이 없는 경우도 많고 다른 패키지와의 관계를 정의한 메타데이터도 갖고 있지 않는 경우도 많았다. 이런 상황에서 의존 라이브러리 정보를 저장할 수 있도록 pip의 requirements 파일을 생성하는 기능이 제공되게 되었다. 대부분의 requirements 파일은 다음과 같은 모습을 하고 있다.
# 이 플래그의 주소는 pip의 기본 설정이지만 관계를 명확하게 보여주기 위해 추가함
--index-url https://pypi.python.org/simple/
MyPackage==1.0requests==1.2.0bcrypt==1.0.2
이 파일에서는 각 의존성 라이브러리 목록을 정확한 버전 지정과 함께 확인할 수 있다. 라이브러리에서는 넓은 범위의 버전 지정을 사용하는 편이지만 어플리케이션은 아주 특정한 버전의 의존성을 갖는다. requests가 정확하게 어떤 버전이 설치되었는지는 큰 문제가 되지 않지만 이렇게 명확한 버전을 기입하면 로컬에서 테스트하거나 개발하는 환경에서도 프로덕션에 설치한 의존성과 정확히 동일한 버전을 사용할 수 있게 된다.
파일 첫 부분에 있는 --index-url https://pypi.python.org/simple/ 부분을 이미 눈치챘을 것이다. requirements.txt에는 PyPI를 사용하지 않는 경우를 제외하고는 일반적으로 인덱스 주소를 명시하지 않는 편이지만 이 첫 행이 requirements.txt에서 매우 중요하다. 이 내용 한 줄이 추상 의존성이었던 requests==1.2.0을 “구체적인” 의존성인 “https://pypi.python.org/simple/에 있는 requests 1.2.0″으로 처리하게 만든다. 즉, 더이상 덕 타이핑 형태로 의존성을 다루는 것이 아니라 isinstance() 함수로 직접 확인하는 방식과 동일한 패키징 방식이라고 할 수 있다.
추상 의존성 또는 구체적인 의존성에는 어떤 문제가 있을까?
여기까지 읽었다면 이렇게 생각할 수도 있다. setup.py는 재배포를 위한 파일이고 requirements.txt는 배포할 수 없는 것을 위한 파일이라고 했다. 그런데 이미 requirements.txt에 담긴 항목이 install_requires=[...]에 정의된 의존성과 동일할텐데 왜 이런 부분을 신경써야 할까? 이런 의문이 들 수 있을 것이다.
추상 의존과 구체적 의존을 분리하는 것은 중요하다. 의존성을 두 방식으로 분리해서 사용하면 PyPI를 미러링해서 사용하는 것이 가능하게 된다. 또한 같은 이유로 회사 스스로 사설(private) 패키지 색인을 구축해서 사용할 수 있는 것이다. 동일한 라이브러리를 가져와서 버그를 고치거나 새로운 기능을 더한 다음에 그 라이브러리를 의존성으로 사용하는 것도 가능하게 된다. 추상 의존성은 명칭, 버전 지정만 있고 이 의존성을 설치할 때 해당 패키지를 PyPI에서 받을지, Create.io에서 받을지, 아니면 자신의 파일 시스템에서 지정할 수 있기 때문이다. 라이브러리를 포크하고 코드를 변경했다 하더라도 라이브러리에 명칭과 버전 지정을 올바르게 했다면 이 라이브러리를 사용하는데 전혀 문제가 없을 것이다.
구체적인 의존성을 추상 의존성이 필요한 곳에서 사용했을 때는 문제가 발생하게 된다. 그 문제에 대한 극단적인 예시는 Go 언어에서 찾아볼 수 있다. go에서 사용하는 기본 패키지 관리자(go get)는 사용할 패키지를 다음 예제처럼 URL로 지정해서 받아오는 것이 가능하다.
import (
"github.com/foo/bar"
)
이 코드에서 의존성을 특정 주소로 지정한 것을 볼 수 있다. 이제 이 라이브러리를 사용하다보니 “bar” 라이브러리에 존재하는 버그가 내 작업에 영향을 줘서 “bar” 라이브러리를 교체하려고 한다고 생각해보자. “bar” 라이브러리를 포크해서 문제를 수정했다면 이제 “bar” 라이브러리의 의존성이 명시된 코드를 변경해야 한다. 물론 지금 바로 수정할 수 있는 패키지라면 상관 없겠지만 5단계 깊숙히 존재하는 라이브러리의 의존성이라면 일이 커지게 된다. 단지 조금 다른 “bar”를 쓰기 위한 작업인데 다른 패키지를 최소 5개를 포크하고 내용을 수정해서 라이브러리를 갱신해야 하는 상황이 되고 말았다.
이 setuptools의 의존성 링크 “기능”은 의존성 라이브러리의 추상성을 지우고 강제로 기입(hardcode)하는 기능으로 이 의존성 패키지를 정확히 어디에서 찾을 수 있는지 url로 저장하게 된다. 이제 Go에서 살펴본 예제처럼 패키지를 조금 수정한 다음에 패키지를 다른 서버에 두고 그 서버에서 의존성을 가져오는 간단한 작업에도 dependency_links를 변경해야 한다. 사용하는 패키지의 모든 의존성 체인을 찾아다니며 이 주소를 수정해야 하는 상황이 되었다.
다시 사용할 수 있도록 만들기, 같은 일을 반복하지 않는 방법
“라이브러리”와 “어플리케이션”을 구분해서 생각하는 것은 각 코드를 다루는 좋은 방식이라고 할 수 있다. 하지만 라이브러리를 개발하다보면 언제든 _그 코드_가 어플리케이션처럼 될 때가 있다. 이제는 setup.py에 기록한 추상 의존성과 requirements.txt에 저장하게 되는 구체적 의존성으로 분리해서 의존성을 저장하고 관리해야 한다는 사실을 알게 되었다. 코드의 의존성을 정의할 수 있고 이 의존성을 받아오고 싶은 경로를 직접 지정할 수 있기 때문이다. 하지만 의존성 목록을 두 파일로 분리해서 관리하다보면 언젠가는 두 목록이 어긋나는 일이 필연적으로 나타난다. 이런 상황을 해결할 수 있도록 pip의 requirements 파일에서 다음 같은 기능을 제공한다. setup.py와 동일한 디렉토리 내에 아래 내용처럼 requirements 파일을 작성하자.
--index-url https://pypi.python.org/simple/
-e .
이렇게 파일을 작성하더라도 pip install -r requirements.txt 명령을 실행해보면 이전과 다르지 않게 동작하게 된다. 이 명령은 먼저 파일 경로 .에 위치한 라이브러리를 설치한다. 그리고 추상 의존성을 확인할 때 --index-url 설정의 경로를 참조해서 구체적인 의존성으로 전환하고 나머지 의존성을 마저 설치하게 된다.
이 방식을 사용하면 또 다른 강력한 기능을 활용할 수 있다. 만약 단위별로 나눠서 배포하고 있는 라이브러리가 둘 이상 있다고 생각해보자. 또는 공식적으로 릴리스하지 않은 기능을 별도의 부분 라이브러리로 분리해서 개발하고 있다고 생각해보자. 라이브러리가 분할되어 있다고 하더라도 이 라이브러리를 참조할 때는 최상위 라이브러리 명칭을 의존성에 입력하게 된다. 모든 라이브러리 의존성은 그대로 설치하면서 부분적으로는 개발 버전의 라이브러리를 설치하고 싶은 경우에는 다음처럼 requirements.txt에 개발 버전을 먼저 설치해서 개발 버전의 부분 라이브러리를 사용하는 것이 가능하다.
이 설정 파일은 먼저 “bar”라는 이름을 사용하고 있는 bar 라이브러리를 https://github.com/foo/bar.git 에서 받아 설치한 다음에 현재 로컬 패키지를 설치하게 된다. 여기서도 의존성을 조합하고 설치하기 위해 --index 옵션을 사용했다. 하지만 여기서는 “bar” 라이브러리 의존성을 github의 주소를 사용해서 먼저 설치했기 때문에 “bar” 의존성은 index로부터 설치하지 않고 github에 있는 개발 버전을 사용하는 것으로 계속 진행할 수 있게 된다.
Python을 실무에서 많이 사용하고 있지 않긴 하지만 사용할 때마다 재미있고 깊게 배우고 싶다는 생각이 늘 드는 언어 중 하나다. 관심을 갖기 시작했을 때부터 PyConAU에 다녀오고 싶었는데 이전엔 브리즈번에서 하고 그 전엔 호바트에서 해서 숙박이나 비행기표나 신경 쓸 일이 많아 고민만 하다 가질 못했었다. 올해는 멜번에서 한다고 하길래 얼리버드 티켓이 열리자마자 구입을 했다. 한동안 python과 가까이 지내지 못해서 과연 내가 이 행사를 참여할 자격이 있는가를 끊임 없이 고민했다. (이미 티켓을 샀으면서도.) 다녀오고 나서는 참 잘 다녀왔구나, 참가 안했으면 얼마나 후회했을까 싶을 정도로 좋은 기억이 남았고 긍정적인 힘을 많이 받고 올 수 있었다.
PyCon AU 2016의 모든 세션은 유튜브에 올라와 있어서 관심이 있다면 확인해보는 것도 좋겠다.
오프닝 키노트는 Python을 작은 임베드 장비에서 구동할 수 있도록 최적화를 먼저 시작하는 방식으로 개발한 구현체인 MicroPython에 대한 이야기였다. 구현을 시작한 과정부터 Kickstarter를 거치며 겪은 경험, BBC와 만든 micro, 그 이후 유럽우주국과 함께 진행한 프로젝트와 앞으로의 로드맵을 이야기했다.
임베딩 장비를 좋아하는데 거기서 고급 언어를 사용할 수 없을까 고민하다가 Python을 공부해야지 하는 마음에 Python을 선택했다는 말도 기억에 남는다. 작게 시작했지만 전환점이 되는 위치가 있었다. 요즘은 이미 거의 완제품이 나온 상태에서 킥스타터에 올리는 분위기지만 MicroPython이 펀딩을 진행했을 당시에는 좀 더 언더(?)같은 느낌이었나보더라. 그렇게 펀딩에 성공해서 MicroPython이 탄생했는데 그게 끝이 아니라 유럽우주국에서 연락이 와 투자를 받았단다. 지금까지 우주에서 사용하는 대부분의 디바이스는 중단 후 컴파일한 소프트웨어를 업데이트하고 다시 구동하는 방식인데 인터프리팅이 가능한데다 고급 언어인 파이썬을 사용할 수 있다는 점에 매력이 컸다고. 유럽우주국과 진행한 프로젝트에서 가능성을 확인했고 추후 장기적인 프로젝트를 계속 진행하게 될거라고 했다.
개발을 시작한 이유도 그렇고 킥스타터나 유럽우주국 이야기, 그렇게 우주로 나가는 디바이스를 만들고 있다는 이야기가 마치 소설처럼 느껴졌다. 작지만 세상을 바꾼다, 느낌으로.
RULES FOR RADICALS: CHANGING THE CULTURE OF PYTHON AT FACEBOOK
페이스북의 이야기였는데 Python2.x에서 Python3.x로 어떻게 옮겼는지에 대한 이야기였다. 2013년부터 이전하자는 이야기를 했는데 2016년에 py3를 기본으로 사용하기까지 과정을 보여줬다.
2013
Linter에서 __future__를 자동으로 넣어줘서 사람들이 아무 생각없이 쓰기 시작함.
원래는 gevent와 twist가 py3 지원할 때까지 기다리려 했는데 Thrift에서 py3 지원 시작하면서 이전하기 시작.
자신이 원하는게 있으면 자신이 먼저 변해야 한다는 이야기, 미래지향적으로 교육을 해야한다는 부분, 통계를 잘 수집하면 이런 과정이 더 명료해서 도움이 된다는 점이 기억에 남는다.
Python for Bioinformatics for learning Python
제목만 보고 Bioinformatics에 대한 이야기를 할 줄 알고 들어갔는데 좀 실망했다. Bioinformatics에서 c++를 자주 사용하는데 가르치기 어려워서 파이썬을 사용하기 시작했다고. Bioinformatics에서 분석할 때 사용하기 좋은 함수가 어떤 것인지 설명해주고 코드골프만 실컷 보여줬다.
Linear Genetic Programming in Python Bytecode
제네릭도 아니고 제네틱은 무엇인가 싶어서 들어갔는데 너무 충격적이었다. 이전에 본 적 있던 유튜브 영상으로 시작했다. 이게 바로 제네틱 프로그래밍이라고.
아예 처음 듣는 이야기라서 좀 어렵긴 했는데 간단히 설명하면 진화론 아이디어를 반영한 프로그래밍 방식이었다. 먼저 코드에서 가족군을 만들고 나올 수 있는 경우의 수를 모두 만들어낸다. 그리고 각 코드끼리 비교 평가를 수행하고 적자 선택을 반복적으로 수행해서 목적에 맞는 코드를 만드는 방식이라고. 평가와 선택이 적절하면 세대를 거듭할수록 목적에 맞는 코드가 나온다고 한다. 들으면서 하나도 모르겠는데 이게 엄청 멋진건 알겠더라. 이 프로그래밍으로 이용해서 전자기판 최적화를 하는 대회(Humis contest)가 있다고 한다.
이 제네틱 프로그래밍을 사용할 때는 함축적인 언어를 사용할수록 유용하다고 하며 brainfuck을 예로 들었던 것이 기억난다.
이 정반합 과정을 Python Bytecode를 사용할 수 있도록 만든 라이브러리 DEAP를 소개했다. 시간이 없어서 Bytecode 예제는 보여주지 못했다.
Security Starts With You: Social Engineering
Social Engineering으로 보안에 취약할 수 있는 정보를 빼내는 방법에 대해 설명했다. 흔히 알고 있는 Phishing 외에도 Tailgating(piggybanking), pretexting, Baiting 등 다양한 방식이 있다고 한다.
기억에 남는 부분은 서비스에서 알림과 같은 이메일을 보낼 때 되도록이면 링크를 넣지 않는 방식으로 하는 것이 보안성이 높다는 이야기였다. 물론 이메일을 받으면 보낸 사람이나 내용을 보면 이미 스팸같은 냄새가 나서 사람들이 안누르긴 하지만 내용이 정말 지능적으로 똑같이 만들어졌다면 평소와 같이 누르게 된다는 것이다. 애초에 메일에 디테일을 담지 않고 자세한 내용은 웹사이트에 로그인하면 확인할 수 있다는 식으로 이메일 자체에 내용을 최소화하는 접근 방식을 사용하면 사람들이 피싱 메일을 받아도 아무 링크나 눌러보지 않도록 하는데 도움을 많이 준다고 한다.
Behind Closed Doors: Managing Passwords in a Dangerous World
password는 신원 확인을 위한 것인데 어떤 방식으로 확인을 하는가, 그 확인을 위한 데이터를 어떻게 보관하는가에 대해서 이야기했다. 보안과 관련한 수많은 라이브러리를 설명해줬다. 점심 먹고 졸릴 시간인데다 라이브러리를 너무 많이 이야기해서 그냥 멍했다. 필요한 권한만 최소로 주라는 말이 기억난다.
CPython internals and the VM
Python을 사용하면서 내부는 어떻게 구현되어 있을까 궁금해서 CPython 코드를 열어봤다는 이야기로 시작해서 코드만 실컷 읽고 끝났다. 오픈소스는 구현이 궁금하면 열어볼 수 있다는 매력이 있다. 어떤 방식으로 돌아가나 그런거 보여줄 줄 알고 갔는데 코드만 읽음.
The dangerous, exquisite art of safely handing user-uploaded files
파일을 업로드 할 수 있는 상황에서 어떻게 올린 파일을 다룰 것인지에 대한 이야기. 파일명이나 파일 확장자는 절대 믿지 말고 고립된 환경에서 파일을 다룰 것에 대해 이야기했는데 PHP를 엄청 깠다. 그다지 새롭지 않았음.
Lightning Talks
5분 짜리 라이트닝 토크를 연속해서 진행했다. pyaudio와 quitnet을 사용해서 스피커로 데이터를 전송하고 마이크로 데이터를 전송 받는 데모도 재밌었다. 여성 스피커로만 진행하는 KatieConf 이야기도 재밌었다. (패러디지만.) 가장 기억에 남는 토크는 Falsehoods Programmers Have about Identity 였다. 이름, 성(Gender), 생일, 국적에 대해 정보를 받을 때 어떤 방식으로 다양성을 존중해야 하는 것인지에 대한 이야기를 했다. 누군가의 정체성을 부정하는 것은 인간임을 부정하는 것과 마찬가지라는 말이 기억에 남는다.
2일차
Python All the Things
파이썬을 사용해서 앱을 개발할 수 있는 PyBee 소개였다. 언어 구현과 레퍼런스 구현을 분리해서 설명했는데 Django와 같이 재단을 만들어서 운영하는 로드맵을 얘기해줬다. 아직 개발이 한창 진행중이라서 실제로 보여주는 부분은 많이 없었지만 그간 파이썬에서 약하다고 생각했던 부분이라 그런지 사람들 관심이 참 많았다.
Evaluating fire simulators using Docker, Dask and Jupyter notebooks!
호주 기상국(Australia Bureau of Meteorology)에서 발표한 세션인데 주제대로 산불 발생 시뮬레이터를 docker와 dask를 사용해서 구현하고 Jupyter로 결과를 가공하는 과정을 보여줬다. docker 때문에 들어갔는데 생각보다 별 내용 없이 개괄적인 이야기를 많이 했다.
Code the Docs: Interactive Document Environments
문서화에 관한 이야기라고 생각했는데 조금 달랐다. 스피커는 사실 Swift 책을 쓰는 사람이었고 Xcode Playground에서 인터렉티브한 개발 문서를 작성해 프로그래밍을 더 쉽게 이해하고 공부하는데 도움이 된다는 내용이었다. 문서와 코드를 오가면서 실제로 동작하는 코드를 확인하는 과정을 문서 내에서 바로 실행할 수 있는, 동적인 문서 환경을 jupyter와 Playground를 사용해서 보여줬다. Oreilly에서 jupyter를 이 용도로 수정해서 교육 프로그램을 운영하고 있다고 Regex golf를 보여줬는데 영상과 문서, 코드가 잘 동기화되어 있었다. 얘기로는 이런 방식의 미디어가 교육을 위한 책을 대체할 것이라고 했는데 교육을 위한 포맷이 다양해져야 한다는 점은 많이 공감했다.
Deciding between continuity and change in your Open Source community
지금까지 커뮤니티를 운영하고 컨퍼런스를 개최하며 겪은 이야기를 공유했다. 오고 가는 자원봉사자와 어떻게 함께하는지, 커뮤니티에서 어떤 부분을 지향해야 하는지, 커뮤니티에 관한 다양한 주제를 이야기했다. 이상한모임에 참여하면서 생각했던 많은 고민이 우리 만의 문제가 아니라 커뮤니티를 운영하면 누구나 고민하는 부분이구나 생각할 수 있었다. 자전거 그늘처럼 불필요한데 시간과 자원을 많이 소모하는 일을 최대한 피해야 한다는 이야기도 기억에 남는다.
Functional Programming for Pythonistas
루비 개발자인데 파이썬의 함수형 프로그래밍에 대해서 이야기했다. map과 같은 함수랑 lambda 설명하는 수준이었다.
The Evolution of Python Packaging at Facebook
페이스북에서 Python 패키지를 어떤 방식으로 배포하는지에 대한 설명이었다. 좀 더 특별한 방식을 사용할거라 생각했는데 ZIP 압축을 그대로 사용한다고 한다. ZIP을 에디터로 열어보면 PK라는 매직 키워드가 존재하는데 그 앞에 shell script를 넣어도 zip파일엔 영향이 없다고 한다. zip파일에 쉘 스크립트를 포함한 후에 쉘로 그 파일을 실행하면 압축을 해제하기 전에 해야 하는 환경 설정이나 라이브러리 처리를 한 다음 self extract 하는 방식으로 사용한다고 한다. 얼마 전 zip을 대체하는 라이브러리를 페이스북에서 발표했다는 소식이 있었는데 아마 이 환경에서 좀 더 편하게 쓸 수 있도록 개선한게 아닌가 싶다.
그 쉘 스크립트를 포함한 zip을 PAR이라 부르고 페이스북 내에서 사용하는 아카이빙 파일로 표준처럼 사용하고 있다고 한다. 배포해야 하는 서버가 많으니까 별도의 프로그램 없이 최소한의 자원을 써서 설치할 수 있는 환경을 만든 모양이다. 이렇게 만든 파일을 rsync하거나 torrent로 배포한다고. 페이스북이 종종 내려가는 이유가 여기에 있다고 하는데 서버에서 한 번 실행하는 함수라서 작은 환경에서 실행했을 때는 문제가 없다가도 수십 만 대 서버에 배포되면 순식간에 수십 만 번 실행하기 때문이라고 한다.
이 발표에서 페이스북의 문화를 중간 중간 이야기했는데 자신이 하고 싶은 일을 스스로 찾아서 재미있게 한다는 점이 참 인상적이고 부러웠다.
Predicting the TripleJ Hottest 100 With Python
이틀 꼬박 달리니까 좀 지쳐서 쉬는 마음으로 들어간 세션이었다. 모 사이트에서 음악 인기투표를 진행하는데 인기투표 후에 소셜로 공유하는 기능이 있어서 그 내용을 분석해 실제 발표 이전에 해당 발표를 예측하는 서비스를 만든 후기였다. 나는 처음 듣는 사이트였지만 그 순위 가지고 베팅도 하고 그렇다고. raw 데이터를 어떻게 가공하고 분석했는지 설명하는데 그냥 수작업으로 보였다.
Hitting the Wall and How to Get Up Again – Tackling Burnout and Strategies
왜 개발자는 번아웃 되고 힘들게 되는가에 대한 이야기였고 바쁘고 힘든 시기여서 그랬는지 많이 위로가 되었다. 힘든게 당연한 일이고 힘들면 꼭 심리치료사를 찾으라고.
Lightning Talks
역시나 다양하고 재미있는 이야기가 많았다.
How well do we (in this room) represent python programmers?: 다양성에 대해 이야기하지만 개발 환경의 다양성에 대한 논의는 적다고. Python을 사용하는 환경이 대부분 리눅스나 맥인 경우가 많은데 실제 학습 환경에서는 윈도를 더 많이 사용하고 있다는 이야기.
5 Languages in 5 minutes: 5가지 언어를 보여줬는데 ARNOLDC, TRUMPSCRIPT, LOLCAT, BRAINF* 4가지와 직접 만든 ANGUISH를 보여줬다. ANGUISH는 공백 언어로 만든 프로그래밍 언어, 매우 안전(?).
Open source and social responsibility: 오픈소스에 사용된 코드 라인 수를 보여줬다. Ubuntu, nginx, postgreSQL, python의 코드를 합치면 72,258,475 라인이라고. 이런 코드를 사용하는데 있어서 좀 더 사회적인 책임 의식을 갖고 사용해야 하지 않을까에 대해 이야기했다. 무슨 사회적인 문제를 해결할 수 있을지 짚어 이야기하며 지금 세상을 바꾸라는 이야기로 마무리했다.
개발을 하다보면 눈 앞에 있는 일에 치여서 재미를 느끼지 못할 때가 있다. 세상은 넓고 멋진 사람들을 많은데 내 작업은 작게만 느껴지고 세상을 바꾼다는 포부와는 동떨어진 삶을 사는 기분이 들 때가 있다. 한동안 너무 바빠서 내가 개발을 얼마나 좋아하고 재미있어 하는지, 즐거워하는지 돌아볼 시간조차 없었다는 것을 파이콘에 참석해서야 알게 되었다. 다들 즐겁게, 자신이 하는 일을 이야기하고 공유하는 것을 보고 기분이 많이 좋아졌고 한편으로 위로도 되었다. 부지런히 배워서 컨퍼런스에서 만난 사람들처럼 누군가에게 좋은 영향력을 주는 사람이 되고 싶다.
특수 권한은 setuid, setgid, 스티키(sticky) 비트가 있다. 16비트 중 앞에서 사용한 파일 타입과 접근 권한을 제외한 나머지, 3비트는 특수 권한을 저장하는 비트로 사용한다.
물론 기본적으로 접근하는 사용자의 권한은 앞에서 설정한 접근 권한을 따르게 된다. 접근 권한에서 접근을 허용하지 않은 상태에서는 아래 특수 권한도 동작하지 않게 된다. 접근 권한과 특수 권한을 조합하면 많은 경우의 수가 나오지만 실행 권한이 없으면 의미가 없는 경우도 있어서 실제로 사용하는 방식은 다소 제한적인 편이다.
특수 권한이 있기 때문에 root 사용자가 아닌 사용자도 ping과 같은 명령을 사용할 수 있게 된다. /tmp와 같은 공유 디렉토리도 특수 권한 중 하나를 사용한다.
setuid가 지정되어 있는 파일을 실행하면 해당 파일은 파일 소유자의 권한으로 실행하게 된다. setgid가 지정되어 있는 파일을 실행하면 해당 파일에 지정되어 있는 그룹의 권한으로 실행하게 된다. 물론 애초에 파일에 접근하는 사용자에게 실행하는 권한이 있어야 실행 가능한 것은 마찬가지다. root 권한으로 지정된 프로그램에 이 비트가 적용되어 있다면 실행할 때 root 권한으로 실행 된다는 뜻이다.
이 기능은 보안상 shell script에서는 동작하지 않는다. 실제로 동작을 확인하고 싶다면 작은 C 프로그램을 만들어서 테스트 해볼 수 있다.
chmod를 8진수 표기법과 함께 사용하는 경우에는 주로 3자리로 많이 사용하지만 4자리로 사용하면 첫 번째 숫자가 특수 권한에 해당한다. 즉, chmod 700은 chmod 0700과 동일하다. 만약 특수 권한이 지정되어 있는 디렉토리에 chmod 700 식으로 지정하면 기존의 특수 권한이 모두 사라지기 때문에 주의해야 한다.
특수 권한으로 인한 보안 문제
특수 권한은 일반적인 파일 접근 방식과 다르기 때문에 사용에 주의해야 한다. 특히 root 권한으로 실행되도록 setuid가 지정된 프로그램에 보안 취약점이 있다면 공격 대상이 될 수 있다.
퍼미션은 가장 기초적인 수준이다. 좀 더 편리하게 사용할 수 있는 ACL도 있고 SELinux를 사용해서 더 보안성 높은 환경을 구축할 수도 있다. 최근에는 서버 가상화로 아키텍처 수준에서의 권한 분리가 이뤄진다. 상황에 맞는 기능을 선택해서 사용하도록 하자.
호주에서도 한국 운전면허증을 NATTI 공증이나 영사 공증 받으면 면허증과 이 공증 서류를 휴대하는 것으로도 운전하는데 아무 지장이 없다. 빅토리아 주에서는 한국 운전면허증를 소지한 경우에 빅토리아 주 운전 면허로 교환해주는 정책이 몇 년 전부터 시작되었는데 다녀오기 귀찮기도 하고 공증 서류만으로도 차량을 렌트해도 전혀 문제가 되지 않아서 바꾸지 않고 있었다. 그런데 영주 비자를 받은 이후 3개월 이내로 바꾸지 않으면 운전 면허를 처음부터 취득해야 한다는 얘기가 있어서 바꾸게 되었다.
VicRoads에 전화(13 11 71)해서 방문 예약을 하면 된다. 한국 운전면허 변경하겠다 하고, 개인 정보 불러주고, 장소 결정하면 예약이 끝난다. 준비할 서류는 다음과 같다.
약속 시간보다 일찍 도착했고 직원 도움을 받아서 신청서를 모두 작성했다. 3년 기한은 77.90불, 10년은 267불이다. 서류 모두 검토하고 사진까지 즉석에서 촬영했다. 운전면허증이 도착하기 전까지는 영수증을 운전면허 대용으로 사용할 수 있다고 한다. 업무일 5일 내로 우편으로 보내준다.
앞으로 얼마나 운전할 일이 있을까 싶기도 하지만 여권 대신 들고 다닐 신분증이니 마음에 평안이 다 생긴다. 😀
신형 맥북 에어가 나오면 구입하려고 그랬는데 생각보다 빨리 나오질 않아서 현행 버전을 구입해야 하는지 고민하고 있었다. 그런데 번역 작업에 MS 워드를 사용하기 시작하면서 윈도 환경이 필요했고 기존 노트북이 워낙에 낮은 사양이라서 작업중에 자주 멎어버렸다. 윈도 환경에서도 이제 Docker도 hyper-v로 사용할 수 있고 조만간 애니버서리 업데이트에서 Bash를 지원할 예정이란 점에서 마음이 많이 갔다.
신형 맥북 에어가 나올지 안나올지도 모르는 상황에 새 맥북에 적용된 키보드라면 별로 구입하고 싶지 않고 16GB 램을 넣어주는 것은 프로 모델에서만 할 것같았다. 이런 추측과 고민 끝에 요즘 MS 스택의 기술에 관심이 많아지고 있는 상황이라 차라리 성능 좋은 윈도 노트북을 구입하기로 마음 먹게 되었다.
윈도 환경의 노트북은 종류가 워낙에 많고 제조사마다 드라이버 최적화 정도도 다르고 서비스 품질도 다른 데다 스펙까지 조금씩 달랐던 탓에 선택의 폭이 워낙 넓었다. 심지어 같은 브랜드인데도 기종별, 세대별로 다 성능이 다른데 깔끔하게 성능을 비교해볼 수 있는 페이지를 제공하는 업체가 정말 적었다. 구입 후보로 골랐던 노트북은 다음과 같다.
Dell XPS 13 9350
Lenovo X1 Carbon
HP Spectre
HP Elitebook Folio G1
HP Folio는 정말 얇고 아름답고 구입하고 싶었지만 호주에서 워낙 비싼 데다 높은 사양은 아직 제공하고 있지 않았다. Spectre도 이뻤지만 역시 가격이, X1도 좋았지만 가격이… 이 중에서 i7 6560U, 16GB, SSD 옵션으로 가장 저렴한 모델이 XPS 13이라서 이 기종으로 구입하게 되었다.
애플이 노트북을 소형화 하기 위해 납땜보드를 선보인 이후에 모든 노트북이 램을 납땜하고 있어서 애초에 램을 크게 구입해야 하는 금전적 아쉬움이 있었다. 큰 램을 사용하는 노트북은 SSD도 고용량이고 여러모로 가격이 올라갈 수 밖에 없는 방식으로 가격을 책정해둬서 어쩔 수 없었다. 이 기종이 ubuntu를 기본으로 설치한 developer edition이 있는데 아쉽게도 호주엔 출시하지 않았다. 16GB 모델도 없어서 고민하던 찰라에 델 호주 아울렛 웹사이트에 올라와서 바로 구입했다.
XPS 13 모델은 디스플레이의 베젤이 매우 얇은 인피니티 디스플레이를 채용하고 있어서 다른 13인치 노트북과 비교하면 확연히 크기가 작다. 물론 무게는 좀 나가는 편이고 내가 구입한 QHD+ 터치 디스플레이 모델은 좀 더 무거운 편이라서 크기에 비해 묵직한 느낌이 있다. 이전까지 사용했던 Dell Inspiron 11 3000과 비교했을 때 크기는 거의 비슷하지만 확실히 무거운 편이다. 물론 인스피론은 플라스틱이고 XPS13은 알루미늄인 탓이 크다.
검색해보면 XPS 13의 고질적인 문제가 몇 존재하는데 키보드에 있던 문제는 얼마 전에 키보드를 교체해서 해결했다. 다른 업체는 어떤지 모르겠는데 Dell은 수리 기사분이 출장와서 직접 고쳐주는 On-site 서비스를 제공하고 있어서 편리했다. (iMac 들고 수리하러 지니어스 바까지 들고 갔던 것을 생각하면…) 문제라고 생각했던 부분이 고쳐져서 다행이다.
얼마 사용하지 않았지만 사용하면서 좋았던 점을 정리해보면,
QHD 디스플레이가 상당히 만족스러움. 대다수 후기에는 고해상도를 지원하는 프로그램이 적어서 불편하다고 하는데 내가 사용하는 대부분의 프로그램에서는 깔끔하게 나왔음.
크기. 13인치인데 확실히 작다.
내장 스피커. 내장이라는 생각이 안들 정도로 스피커가 괜찮다. 특정 주파수 대역에서 노이즈가 발생하는 문제가 있는데 내 기기에는 문제가 없었다.
단점은,
배터리가 짧음. 디스플레이 탓이라는데 4-5시간 정도 가는 것 같다.
고주파음(high pitch noise). 모델 초기부터 있던 문제라고 하는데 데이터를 읽는 양이 많아지거나 하면 고주파음이 난다. 조용한 공간에서는 소리가 확실히 나서 거슬리는 편이지만 일상적으로는 그냥 무시할만한 수준이다.
맥은 호주오면서 사용하기 시작했고 그 이전까지 윈도 환경을 계속 썼었지만 제대로 윈도 기술 스택을 사용해서 공부해본 적이 없었다. 지금은 관심도 많이 생기고 기술 분야도 다양해져서 윈도 랩탑을 장만한게 괜히 더 기분이 좋아지는 것 같다. 조만간 일들이 좀 정리되고 나면 UWP 등 관심있던 분야를 깊이 있게 공부해보고 싶다.