지난 월요일에 새로운 곳으로 출근하기 시작했다. 멜버른 소재 S대학의 IT 부서에서 PHP/Frontend Developer로 일하게 되었다. 회사를 그만 둬야겠다는 생각을 결심하고 인터뷰 보고 합격하기까지 일주일도 안되는 사이에 모두 이뤄졌다. 전 직장을 너무 오래 다녀서 그런지 새 직장에서 첫 주를 다니고 나서야 좀 실감이 나기 시작했다.
새 사무실 계단에서 기차역이 보인다
호주에서 처음으로 다닌 회사는 저스틴님을 만난 B사가 가장 먼저였지만 거기서는 2주 정도의 계약직이였고 이 레퍼런스로 취업하고 지난 달까지 다녔던 회사는 K사로 4년 10개월을 다녔다. 호주에서 와서 처음으로 제대로 다니기도 했고 지금까지 호주에 있을 수 있도록 비자도 모두 해준 고마운 회사라서 그만 두는 일이 쉽지는 않았다. 전사적으로 여러 시스템을 도입하기도 하고 직접 스크래치한 솔루션도 있어서 내 회사라는 생각이 들 정도로 많은 기억과 감정이 깃든 회사였다.
하지만 적은 인원으로 운용되는 에이전시에 운영/유지보수까지 양이 많아지다보니 본연의 업무보다 “급한” 일을 많이 하게 되서 점점 심적으로 힘들어졌었다. 그래도 작년에는 스스로 어떻게 해결해보려고 오랜 기간 노력을 해봤는데 내 스스로도 퍼포먼스가 떨어지고 집중도 안되는게 느껴져서 너무 괴로웠다. “급한” 일은 이상하게 “급한” 일을 이미 하고 있는데 더 “급한” 일이 나타나서 끝맺지 못한 일만 늘어나게 되는 것 같다. 그랬던 탓에 코드를 만드는 일 자체가 재미없게 느껴질 정도가 되었다. 평소에는 퇴근하고 나면 이런 저런 코드도 만들고 그랬는데 어느 날부터 그냥 넷플릭스 보고 게임만 하고 그랬던 것 같다. 벌여놓은 일도 있었는데 제대로 하지 못한 기분도 들고, 블로그도 꾸준히 못했다. 그렇게 놀고도 다음날 출근하기 싫어서 일찍 자지도 않은 날이 반복되었다.
너무나 내 기분이라서 저장했던 짤
지금 생각해보면 회사 내에서 누군가에게 도움을 요청하지 않고 스스로 해결하려고만 해서 이렇게 되지 않았나 생각들기도 한다. 하지만 회사는 작았고 모두 바쁘기도 하고 누구 붙잡아 얘기하기에는 너무 민감한 이야기기도 했다. 그래서 멜버른 지인들을 커피와 점심/저녁을 핑계 삼아 만나 내 어려움을 늘 토로했는데 맨날 같은 말 하는 나를 만나 잘 챙겨주셨던 모든 분들께 감사 이전에 너무 죄송하기만 하다.
작년 말에 이직을 결정하고 주변 분들에게 이직을 생각한다고 말을 꺼내기 시작했었다. 그러던 중 저스틴님이 한 리쿠르터를 레퍼런스 해주셨는데 이력서를 보내고 하루 지나 인터뷰가 잡히게 되었다. 잔뜩 긴장하고 인터뷰를 갔고 php와 php security, angular, database, linux 기본적인 것들을 물어봤다. 다 일반적인 질문들이라 크게 어렵진 않았는데 데이터베이스 질문에 생각보다 막혀서 좀 조바심이 났다. 리쿠르터 분이 인터뷰 전에 “인터뷰이로 가는게 아니라 비지니스 클라이언트를 만나러 간다고 생각하고 대하라”는 얘기를 해줬는데 그런 각오로 인터뷰에 임했더니 좀 더 자신감이 붙었던 것 같다. 그래서 인터뷰 끝에 질문할 때 프로젝트 요구사항이라든지 코드의 질이나 개발 환경에 대한 질문을 많이 했는데 좋은 인상을 남겼던 것 같다.
호주는 연말에 크리스마스에서 신년 사이 사무실 전체가 휴가를 내는 경우가 많은데 내 인터뷰가 크리스마스 바로 전날이었다. 그날 오후에 리쿠르터한테 붙었다고 연락이 왔다. 그래도 아직 정식 오퍼가 오지 않아서 혹시나 싶어 조용히 지내다가 연휴가 끝나고 제대로 오퍼레터를 받을 수 있었다. (레퍼런스를 해주신 저스틴님과 지만님께 또 감사드린다.)
계약서를 확인해보니 일한 기간에 따라 노티스를 주게 되어 있어서 내 경우는 3주 노티스를 줘야 했다. 처음으로 사직서도 작성했다. Resignation letter template을 한참 검색하고 고민해서 썼다. (짜집기했다의 다른 표현.) 그렇게 써서 제출했더니 너무 갑작스럽다고 바로 수리되지 않았다. 그러고 3일 가량을 설득하려 했다. 그런 후 카운트 오퍼를 줬는데 그 사이 한참 흔들리긴 했지만 작년 한 해 힘들었던 기억도 있고 어짜피 한번 말하고 나면 이전과 같은 관계가 될 수 없다는걸 잘 알고 있기 때문에 그 오퍼를 거절하고 다시 사직서를 제출했다. 그렇게 3주 정리 기간동안 인수인계 기간을 거쳤다. 마지막 날은 오랜 기간 다녀서 기분이 먹먹하긴 했지만 마지막이란 생각에 너무 행복했고 퇴근 후에도 너무 행복했고 다음 월요일 출근 안해서 너무 행복했다. 그래서 잘 그만 뒀구나 생각이 들었다. 잠시 쉬고 새 회사에 출근하게 되었다.
대학교로 출근하는 기분도 신선하고 동네 분위기도 사뭇 달라서 아직 어색하지만 팀원도 좋고 좀 더 체계적인 환경에서 개발하게 되어 기분이 좋다. (대학가라서 점심 먹을 곳이 참 많다!) 첫 주라서 기존 코드를 읽고 업무 파악하고 부트스트랩을 만들려고 노력하고 있는데 조만간 프로젝트가 시작될 예정이라 기대와 걱정이 뒤섞여있다. 이전 조직에 비해 커뮤니케이션과 문서화가 월등히 많아서 개발 자체보다는 영어를 더 열심히 해야겠다는 생각도 했다. 이제 차근차근 준비해나가야겠다.
얼마 전에 okky에 웹 개발자도 개발자라고 할 수 있나요라는 글이 올라왔었다. 원문을 보기 전에 수많은 분들의 반응을 먼저 봐서 그랬는지 몰라도 가볍게 읽고 지나갔다. 이직으로 인한 인수인계에, 책 마무리 작업에, 이상한모임까지 겹쳐 자는 시간 외에는 정말 정신이 없었던 탓이다. 사실 코더랑 프로그래머를 분리해서 이야기하는 사람도 종종 봐왔기 때문에 이런 글은 그렇게 특별하지 않았지만 바쁜 와중에도 이 글이 계속 생각이 났다.
의외로 복사 붙여넣기 코드가 저평가 받는다. 붙여 넣어도 돌아갈 만큼 발달하기까지 얼마나 많은 과정이 수반되었는지 생각해야 한다. 3분 카레를 데워 먹는다고 그게 음식이 아니라고 할 수 없다. 음식이 상하지 않도록 하는 포장 기술도, 가열 도구의 발전도 저변에 깔려 있다. 그리고 공개된 조리법을 사용한다고 요리사가 아니라고 할 수 있을까? 파인 다이닝에서 요리하는 셰프가 스스로 레시피를 개발해서 요리한다 한들 그 사실을 동네 중국집 요리사를 요리사가 아니라고 말할 근거로 사용해서도 안된다. 솔직히 이런 부분은 언급할 필요도 없을 정도로 구차하게 느껴진다.
불편하게 느꼈던 부분은 억대 연봉자, 부당 대우에 관한 이야기다. 이 부분은 개인의 능력과는 별개로 산업 전반에서 필요한, 필수적인 논의다. 그 분야에서 대가가 되어야만 발언권을 갖을 수 있다고 생각하는 것 자체가 시장을 저해하는 요소다. 억대 연봉자가 늘어나면 지금 시작하는 사람들도 더 좋은 연봉을 받을 수 있지 않을까? 설령 잘 못하는 사람이 좋은 대우를 받는다면 잘하는 사람은 지금보다도 더 좋은 대우를 받을 수 있지 않을까? 하나는 낙수효과고 다른 하나는 분수효과에 대한 이야기로 어느 쪽이든 오늘의 환경을 개선하는데 일조한다고 생각한다. 그리고 부당한건 이야기하고 논의하고 연대해야 한다. 게임개발자연대와 같은 활동이 더 많아져야 한다. 적어도 엉뚱한 전제로 사다리를 걷어차지 말아야 한다.
이 트윗을 읽고 반성했다. 일하는 입장에서 프로답게 생각한다는 말에 너무 공감했다. 그래서 내게 있어서 대화가 방해로 느껴지는 경우를 곰곰히 생각해봤다. 대부분 아래 두 가지 경우였다.
대화로 인해 내 작업 순위에 지속적인 영향을 주는 경우
긴 호흡이 필요한 개발에 집중을 깨는 경우
회사(이제는 전 회사)에서 특히 전자가 심했고 개선해보려고 노력했지만 내 스스로 너무 스트레스를 많이 받았다. 대부분 이렇게 갑작스런 대화로 추가된, 짧은 호흡의 개발이 반복되면 내 자신을 갉아먹는 기분이 든다. 회사에서 이런 작업을 제대로 인지하면 다행인데 원래 해야 했던 일을 못하게 된다는 사실을 알지 못하는 경우가 많다. 다른 작업으로 진행하지 못한 일인데 계획대로 진행하지 못했다고 낮은 평가를 받게 된다면 고스란히 대화 자체에 압박을 받게 된다. 왜 커뮤니케이션의 비용을 작업자가 고스란히 떠맡게 되는 것일까? 이런 탓에 결국 업무 시간이 늘고 야근으로 이어지는 경우도 봐왔다.
나에게 집중은 등산처럼 느껴진다. 일을 하지 않더라도 내일, 이번 주, 이번 달 무슨 일을 할 지 계획에 맞춰 내 뇌는 일하지 않는 시간에도 준비를 한다. 그렇게 일의 순서를 생각하고 출근했는데 아침부터 치고 들어오는 수많은, 다른 일이 있다면 오후가 되어도 쉬이 집중이 되질 않는다. 산을 올라가려고 준비한 집중력을 다른데 다 써버렸으니 어쩌면 당연한 일이지만 스스로 계획하고 생각했던 만큼 올라가지 못해서 또 괴롭게 느껴진다. 오늘 할 일을 예측할 수 없게 될 때, 아침에 일어나면 출근이 두려워진다.
대화를 하지 않으면 당연히 일이 되지 않는다. 하지만 누군가의 우선순위를 바꾸는 대화는 좀 더 조심할 필요가 있다고 생각한다. 급한 일 카드를 남용하면 더 급한 일, 더 더 급한 일 카드도 금방 생겨나기 때문이다. 일의 순서가 바뀌는 상황을 잘 보고 그 일로 다른 업무가 밀리는 상황을 잘 봐야한다. 일을 주는 입장에서는 이 부분을 간과하기 쉽다. 작은 일이라도 이슈 트래커 등 모두가 작업 순서의 변화를 인지할 수 있는 경로를 통해 전달되어야 한다. 급한 일을 대비한 버퍼도 있어야 한다. 끼어드는 일거리의 중요도가 낮다는 이야기가 아니다. 대신 이런 일감을 어떻게 주고 관리하느냐는 회사의 역량이 들어나는 부분이라 생각한다.
대화가 방해가 된다고 느껴진다면 그냥 지나칠 것이 아니라 업무환경 적신호로 느껴야 한다. “대화탈출버튼”을 만들어서 나눠주지 않는다면 누군가는 그 짐을 고스란히 얹고 지내다가 “회사탈출버튼”을 눌러버릴 것이다. 더 빨리 눌렀어야 했다는 생각과 함께 말이다.
이상하게 집이나 회사에서 한국어 웹사이트를 접속하면 종종 한글이 제대로 표시되지 않는 문제를 겪고 있었다. 사파리에서는 그렇게 동작하지 않는 것 같은데 크롬에서는 자주 깨진 모습으로 나타난다.
증상은 웹페이지에서 한글이 깨진 문자로 나온다는 점이다. 이 문제는 웹폰트를 사용할 때 주로 나타난다. 웹폰트 외에 한글에 대한 fallback 폰트를 직접 지정하지 않은 이상 sans-serif를 넣더라도 기본 폰트가 적용되지 않는다.
예로 시아님의 포스트를 보면 다음처럼 깨진 모습으로 나타난다. 이 포스트는 그래도 본문은 나오고 있지만 본문도 전부 깨지는 경우도 있다.
해결 방법은 폰트를 지정하면서 웹폰트 뒤에 'apple sd gothic neo', 'nanum gothic'와 같이 국문 폰트도 명시적으로 넣어주면 일단 깨지지 않고 동작한다. 내 블로그의 경우에도 이 방식을 사용하고 있다.
또 다른 해결 방법은 html 요소에 lang 속성을 지정해주는 방법이다.
<html lang="ko">
이러면 fallback을 위한 폰트를 직접 지정하지 않아도 한글이 제대로 출력된다.
이 사실을 발견하고 나서는 블로그에서 깨진 한글을 볼 때마다 lang 속성이 무엇으로 지정되어 있는지 소스를 확인하게 된다. 의외로 github에 올라온 대부분의 정적 블로그가 테마에서 지정한 lang을 그대로 사용하고 있었다. 유독 lang="de"로 지정된 블로그가 많았는데 독일에서 만든 테마를 많이 사용하고 있는걸까.
구글 웹폰트는 최근 unicode-range도 같이 제공하기 때문에 이 영향은 아닐까 확인해봤는데 차이가 없었다.
사실 이 문제를 겪은지 꽤 되었는데 나만 겪고 있는 문제인 것 같기도 하고 통제된 환경에서 제대로 된 재현을 해보지 않았기 때문에 알고만 있었지 따로 정리하지는 않았었다. 게다가 크롬에서만 발생하는 문제기도 해서 정 급하면 사파리로 열어서 봤기 때문에 언젠가 크롬이 고쳐지지 않을까 생각했는데 일시적인 문제는 아닌 것 같다.
급한 작업이 끝난 이후로 먼지 수집기 역할을 하던 Dell XPS 13을 어제 중고 거래로 정리했다. 검트리에 올렸더니 온갖 사람들이 700불 800불을 깎으려 들어서 한동안 스트레스였는데 한 달 만에 올린 가격에 산다는 사람이 나타났다.
XPS 13도 좋은 노트북이다. 16GB 램도 올릴 수 있고 리눅스를 설치해도 전혀 문제 없이 구동할 수 있었다. 그래서 정을 붙여보려고 애썼는데 몇 가지 거슬리는 부분이 있어서 영 적응을 못했다.
키보드가 좀 이상하다. 키감이 얇은 것 이상으로 뭔가 이상하다. 처음 받았을 때는 몇몇 키가 눌리는 느낌이 없어서 키보드 교체를 받았었다. 눌리지 않은 증상은 개선되었지만 여전히 어색했다.
터치패드. 마우스 연결하기 위해 블루투스 켜는 용으로 달아놓은 수준. 물론 마우스를 들고 다니면 되겠지만…
고주파음이 상당히 거슬렸다. 이전 글에서도 썼지만 조용한 곳에서는 너무 잘 들린다. 노트북은 자기 전에 가장 많이 사용하는데 일정한 고주파음도 아니고 스크롤 할 때마다 노래하듯 나는 소리는 참기 힘들었다.
발열이 상당히 거슬린다. 게다가 펜이 돌기 시작하면 컴퓨터 끄기 전까지는 펜이 멈추지 않는다. 겨울에는 덕분에 따뜻했다.
베터리 인디케이터가 지나치게 들쑥날쑥하다. 이건 하드웨어 문제인지 윈도 문제인지 모르겠는데 남은 퍼센트나 시간 표시만 믿었다가는 들고 나가서 켜자마자 죽는 것을 볼 수 있다.
노트북 무게중심이 잘못된 것인지 한 손으로 뚜껑을 들어올릴 수가 없다.
충전하면 어뎁터에 빛이 들어오는데 상당히 거슬릴 정도로 빛이 밝다. 불 끄면 거의 무드등 수준.
적고 보니 엄청 까탈스러운 사람이 된 기분이다. 물론 좋은 부분도 있었다. 디스플레이도 엄청 좋았고, 화면 터치도 가능했고(거의 쓰진 않았지만), 무엇보다 가격대비 스펙은 상당히 높다. 애써 친해지려고 노력했던 그간의 노력 때문인지 물건 건내주고 돌아오는 동안 쓸쓸한 기분이 들었다. 속도 시원하긴 하지만.
한동안은 크게 노트북 쓸 일이 없으니 이직한 후에 교직원 할인 받아서 애플 제품을 사던지 할 생각이다. 맥북 에어를 사용할 때 단 한번도 생각해보지도 불편하다고 느껴보지도 못한 부분에서 너무 시달린 터라 그냥 맥북을 사게 될 것 같다.
요즘 생각도 많고 일도 바뻐서 블로그에 글 하나 올리지 않고 있다. 신년에는 글도 더 많이 쓰고 책도 많이 읽으려고 하는데 첫 주에 아무 것도 못하고 지나가고 말았다.
글을 쓰면, 특히 블로그에 글을 올리면 이런 생각이 들거나 이런 이야기를 듣게 된다.
안쓰는 것보다 쓰는 것이 낫다
쓸거면 잘 쓰는 것이 낫다
이 두 생각은 다양한 방식으로 변주되는데 가장 피곤한 형태는 “잘 쓰지 못한다면 안쓰는 것이 낫다”고 생각하는 일이다. 이런 생각을 본인만 하면 모르겠는데 남이 쓴 글에 이런 말을 하는 사람을 종종 본다. 심지어 이런 이야기를 건설적으로 듣지 못한다면 글 쓸 자격이 없다느니, 자신이 아무 말 해놓고는 그 책임을 글쓴이에게 전적으로 돌리는 경우도 있다. 이러면 글 쓰는 사람은 자신감도 없어지고 이런 대화를 보면 나는 글 쓰질 말아야지 결심하기도 한다. 어느 쪽이나 무서운 일이다.
늘 글을 쓰는 일을 생각하며 지내지만 이런 대화를 듣거나 보고나면 계속 글을 쓰는게 맞나 생각이 맴돈다. 마치 개미지옥과 같아서 벗어나기 쉽지 않다.
먼저, 글을 써보지 않으면 자신이 잘 쓰는지 못쓰는지 알 수 없다. 먹어보지 않은 음식의 맛을 알고 싶다면 물론 인터넷 검색해보면 간접적으로 알 수 있겠지만 직접 먹어보는 것이 확실하다. 게다가 그 글도 한 두 번 써본다고 잘 쓰는지 알기 어렵다. 맛집찾기와 비슷한 과정이다. 많이 먹어보기 전에는 어느 집이 맛있는지 비교하기 힘들다. 자신이 어떻게 글을 쓸 때 즐겁고, 더 깊이 집중하고 싶다는 생각이 드는지 알고 싶다면 꾸준히 써봐야 한다. 100개 포스트 올리기 같은 목표를 만들고 달성해보는 식이다.
그리고 글은 독자가 있어야 다듬어진다. 가장 이상적인 독자는 가까이 있는 사람 중 기꺼이 시간을 내어 글을 읽어줄 분이다. “아는 사람”은 질 높은 피드백을 줄 가능성이 높다. 다만 피드백을 받으면 종종 글의 호흡이나 글 쓰는 과정 전체가 늘어지는 경향이 있다. 짧고 간단한 글이라면 먼저 공개하고 피드백을 받는 것도 좋다고 생각한다.
그리고 좋은 피드백을 받고 싶다면 본인도 평소에 많이 찾아 읽고 피드백을 즐겁게 자주 남겨야 한다. 그렇다고 피드백이 거창할 필요는 없다. 잘 읽었다면 잘 읽었다고, 오타가 있으면 오타가 있다고 말해주는 정도여도 충분하다. 그리고 다른 의견이라면 글 뒤에는 사람이 있다는 것을 잊지 말고 정중하게 쓰자. 기본이다. 피드백을 주는 일은 내 글을 쓸 때도 더 넓은 관점으로 글을 접근할 수 있는 시각을 주는 동시에 새로운 독자를 찾는 기회가 될 수도 있다.
그리고 글이 부족하다고 지적받는 일을 두려워하지 않았으면 좋겠다. 내 스스로도 여전히 두려운 일이긴 하지만 “지적 받으면 더 고민해보고 고치면” 된다. 그런 면에서 블로그는 매우 편리하다. 문제가 생기면 고치거나 글을 내릴 수 있기 때문이다.
마지막으로 맞춤법 검사를 수행하고 비문을 사용하지 않았는지 확인한다. 이 두 가지는 글을 읽는 과정을 방해하며 글이 전달하는 내용을 흐리게 된다. 맞춤법 검사 도구를 사용해보고 글을 꼼꼼하게 읽어 비문을 수정하자.
올해는 내 스스로도 글쓰기 개미지옥에서 탈출하도록 노력할 계획이다. 더 부지런히 글을 쓸 수 있었으면 좋겠다.
2016년 들어온 지 얼마 되지 않은 것 같은데 벌써 시간이 이렇게 지났다. 상투적이지만 어째 한해 한해 더 빠르게 지나가는 기분이다. 올해는 바쁘다는 핑계로 경험을 글로 정리하지 못했는데 아무래도 저지른 일이 많다보니 한번에 풀어내기 쉽지 않은 탓도 있는 것 같다. 이상한모임에서도 올해 배운 것이라는 주제로 대림절 달력이 진행되고 있는데 달력에 매일 올라오는 글을 보면서 더 미루지 말고 조금이라도 정리해보자는 마음을 먹게 되었다.
올해 했던 일 중 하나가 도서 번역이었다. 이 글은 번역 과정에서 겪었던 경험과 생각을 정리한 포스트다. 번역을 하기 전에 막연하게 생각했던 부분도 실제 과정에서 겪기도 했고 생각과 전혀 달랐던 부분도 있었다. 출판이나 번역 쪽에 오래 계셨던 분이 읽기에는 너무 사소한 이야기일지도 모르겠지만 막 시작하는 입장에서 겪고 생각했던 부분을 정리해보려고 한다.
진행 과정
올해 2월에 출판사에서 페이스북을 통해 연락을 받았다. Practical Vim이라는 도서 번역 의뢰였다. 2015년 말에 올렸던 글이 널리 퍼진 일이 있었는데 그때 블로그를 보고 연락을 주셨다고 했다. 전문적으로 번역을 하는 것은 아니었지만 블로그에 작게나마 글을 번역해서 자주 올리고 있어서 제안이 너무 반가웠다. 특히 Vim은 늘 사용하지만 제대로 사용한다는 자신이 없었는데 이 책을 번역하면 그 가려움도 긁을 수 있지 않을까 생각이 들었다.
하지만 내 번역에 대한 질이나 속도를 정확하게 모르기도 했고 시간이 얼마나 걸리게 될지 예측하기가 어려웠다. 또한 안해본 일에 대한 두려움도 있었고 제대로 번역되지 않은 책에 대해서 뒷얘기도 많이 들었던 터라 쉽게 결정을 내릴 수 없었다. 블로그야 번역 글이 잘못되었다면 수정하거나 다듬거나 모든 일이 내 마음대로 되는데 책은 전혀 그러지 못하니 겁이 앞설 수 밖에 없었다. 그래도 안하면 이런 기회가 언제 다시 올까 싶어서 하겠다는 의사를 전했다.
출판사에서도 계약 전에 일정 분량을 번역해서 보내달라고 했다. 번역 품질이나 속도를 가늠하기 위한, 일종의 면접이였다. 그렇게 여러 장 분량을 번역해서 며칠 후 메일로 발송했다. 몇 차례 추가적으로 다듬는 과정을 거친 후에 큰 문제가 없을 것 같다는 얘기를 듣고 계약서를 작성하게 되었다.
초벌 번역은 6월에 끝났고 첫 교정은 9월에, 두 번째는 11월 초에 마무리했다. 초반에 번역했던 부분과 후반에 번역한 부분을 비교하면 확실히 후반부가 자연스러웠다. 진행하는 동안 문장력이 상승했는지 어쩐건지 모르겠지만 품질이 일관적이지 않았던 탓에 편집자님이 고생을 많이 하셨다.
어려웠던 부분과 배운 점
모든 과정이 도구와의 씨름이었다. 초벌 번역에서는 Vim을 사용해서 작성했지만 원문의 다양한 양식을 반영하는데 쉽지 않았다. 첫 교정에서는 구글독스를 쓰려고 했는데 페이지 분량이 조금만 많아도 속도가 너무 느려서 윈도 노트북을 장만하고 MS 오피스 워드로 전환했다. 워드도 분량이 많아지면 상당히 느려지고 굳을 때가 생각보다 많았다. 작업 과정 중 도구 때문에 고민 안했던 적이 없었는데 디자인으로 옮겨진 후에 PDF 상에서 교정을 볼 때 가장 편하게 느껴졌다.
용어 번역이 쉽지 않았다. 사전적 의미로 옮기는 방식은 가장 쉽지만 기능의 의미를 쉽게 이해할 수 있는지, 오히려 한번 더 생각해봐야 하는 용어는 아닌지 계속 고민할 수 밖에 없었다. 두루 사용되는 용어로 번역해야 할 지, 아니면 음차로 표기를 할 지 단어 하나하나 넘어가기 쉽지 않았다. Vim에서만 사용되는 용어는 참고할 곳도 마땅치 않아서 어려웠다.
번역에 있어 일관성을 유지하는 일도 생각보다 품이 많이 든다. 키워드는 동일한 용어로 번역해야 하는데 영어다보니 이게 키워드로 사용한 것인지 아니면 일반 표현으로 작성한 것인지 모호한 경우도 있었다. 번역을 진행하면서 용어 사전을 만드는게 좋다는 이야기를 들었는데 책 자체가 팁이 나열된 방식이고 각 팁마다 연결된 팁이 언급되어 있어서 그때그때 키워드를 찾는 과정이 그다지 어렵지 않았다. 하지만 나중에 교정에서 많이 후회했다. 생각보다 번역 기간은 길어졌고 그 기간동안 기억이 많이 희미해져서 오가며 찾아보는 과정에 시간을 많이 소비했다.
앞에서도 이야기했지만 긴 글을 번역해본 경험이 없어서 시간 배분이 쉽지 않았다. 각 장, 파트마다 “대략적인” 기간을 산정했는데 너무 안일했다. 시작하기 전에 분량과 내용의 난이도를 판단해서 일별로 작업량을 명확하게 정리할 필요가 있다. 전업 번역가가 아니라면 이 과정이 정말 중요한 것 같다. 책에서 나눠진 팁 단위로 목표를 잡고 진행했는데 각 장이나 팁마다 분량이 각각이라 생각보다 목표에 맞춰 진행하기 어려웠다. 쪽으로 나눠서 하는게 훨씬 편했고 작업 분량 측정이나 목표 달성하는데 훨씬 쉬웠다.
번역에 신경썼던 점
블로그에 번역글을 올리는 것과는 확실히 무게감에서 차이가 있어서 교정에 노력을 많이 했다. 볼 때마다 말도 안되는 문장이 자꾸 보여서 겁이 날 지경이다. 번역과 교정에서 지키려고 노력한 몇 가지 규칙이 있었다. 사소한 부분이긴 하지만 내 스스로 역서를 읽을 때 불편하게 느꼈던 표현이라서 계속 염두하고 진행했다.
피동/사동 표현은 최소로 사용하려고 했다. 피동이 아니면 정말 어색한 경우 외에는 전부 능동으로 적었다. “비주얼 모드에서 영역 선택 기능이 제공된다.” 보다는 “비주얼 모드에서 영역 선택 기능을 제공한다.” 처럼 작성했다.
대명사는 좀 더 명확하게 하고 싶었다. It, this 같은 대명사가 반복되는데 “이 플러그인은”, “이 기능은” 식으로 옮겼다.
복수형 표현에 주의했다. Some of Vim’s commands are 식은 “Vim의 명령들 중에는” 보다 “Vim의 명령 중에는” 처럼 작성했다.
번역 과정 중에 번역에 관한 책을 몇 권 알게 되서 읽어보려고 했는데 번역 사이사이 베타리딩, 이상한모임 행사, 회사일, 호주 체류 관련 업무 등등 수많은 일이 있어 도저히 읽을 여유가 없었다. 위시리스트에 있는 책은 다음과 같다. 각각 읽은 분들 후기를 보면 읽고 나서 번역했으면 얼마나 좋았을까 생각하며 적어뒀다.
내 문장이 그렇게 이상한가요?
번역의 탄생
번역자를 위한 우리말 공부
갈등하는 번역
문장 기술
읽지도 않은 책 목록을 올리는게 이상한 기분이 들긴 하지만 혹시나 해서 넣었다. 연말 휴가 기간 동안에 마련할 수 있는 책은 찾아서 읽어볼 생각이다.
기대보다는 걱정이 더 많이 되는 것이 사실이다. 트위터에서 번역 질이 안좋은 책은 어떤 혹독한 대우를 받고 사는지 자주 봐서 이 책으로 불로장생을 실현하게 될까 걱정이 된다. 더군다나 책에 역자로 내 이름이 올라간다고 해서 나만의 책인 것이 아니라 교정부터 디자인, 출력 등 내가 알기도 모르기도 하는 수많은 손이 함께 한다는 생각이 문득 문득 들어 밥이 넘어가지 않을 때가 있다. 이미 원고가 내 손을 떠나 어떻게 할 수 없는 상황에서도 그런 기분이 든다. 책을 실물로 보면 좀 홀가분해질지, 그때가 되어봐야 알 것 같다.
그리고 한편 뿌듯했던 부분은 블로그에 계속 올린 번역을 보고 연락을 받았다는 점이다. 기술적인 내용이나 유익한 글은 번역하며 꼼꼼하게 보고 더 오래 기억하고 싶기도 했고 같이 읽고 싶다는 생각에 계속 번역을 올렸었다. 이런 번역이 일종의 포트폴리오가 되리라고는 생각을 해보진 못했다. 앞으로 어떻게 될 지 잘 모르겠지만 그래도 예전보다는 조금 더 꼼꼼하게 글을 올리게 될 것 같다.
먼 길을 가도 그 시작은 첫 발을 내딛는 일에서, 구렁이 담 넘어가듯 모던 PHP 넘어가기 시리즈.
흔히 모던 PHP라고 말하는 현대적인 PHP 개발 방식에 대해 많은 이야기가 있다. 새 방식을 사용하면 협의된 명세를 통해 코드 재사용성을 높이고 패키지를 통해 코드 간 의존성을 낮출 수 있는 등 다른 프로그래밍 언어에서 사용 가능했던 좋은 기능을 PHP에서도 활용할 수 있게 된 것이다. 이 방식은 과거 PHP 환경에 비해 확실히 개선되었다. 하지만 아무리 좋은 개발 방식이라 해도 현장에서 쉽게 도입하기 어렵다. 코드 기반이 너무 커서 일괄 전환이 어렵거나, 이전 환경에 종속적인 경우(mysql_* 함수를 여전히 사용), 새로운 개발 방식을 적용하기 위한 재교육 비용이 너무 크고, 신규 프로젝트와 구 프로젝트가 공존하는 동안 전환 비용이 발생할 수 있다는 점이 걸림돌이 된다. 이런 이유로 사내 정책 상 예전 환경을 계속 사용하기로 결정할 수도 있고, 개개인의 선택에 따라 계속 이전 버전을 사용하는 경우도 있을 것이다. 그 결과, 좋은 개발 방식임을 이미 알고 있지만 마치 다른 나라 이야기처럼 느끼는 사람도 많다.
A: 팀장님 모던 PHP 도입합시다 +_+
B:
지금 다니고 있는 회사에서도 모든 코드를 일괄적으로 모던 PHP로 이전할 수 없었다. 가장 큰 문제는 코드란 혼자서만 작성하는 것이 아니며 다른 개발자와의 협업도 고려해야 하기 때문에 구성원 간의 협의가 필요하다. 그래서 일괄적인 도입보다는 점진적으로 코드는 개선해 가면서 새 개발 방식에 천천히 적응하는 방법은 없는지 고민하게 되었다. 작은 코드부터 시작해서 먼저 도입할 수 있는 부분부터 차근차근 도입하기 시작했다. 아직 회사에서 사용하는 대다수의 프레임워크와 CMS가 이전 방식을 기반으로 하고 있기 때문에 100% 모던 PHP를 사용하는 것은 아직 멀었지만, 팀 내에서 작은 크기의 코드인데도 새 방식의 장점과 필요성을 설득하기에 충분한 역할을 할 수 있었다.
레거시 PHP 코드에서 모던 PHP 코드로
이전 PHP 코드를 사용하면서도 현대적인 PHP를 도입하기 위해 고민하고 있다면 도움이 되지 않을까 하는 생각으로 이렇게 정리하게 되었다. 이 글에서 다루는 내용은 내가 소속된 회사에서도 현재 진행형이다. 즉, 이 글을 따라서 해야만 정답인 것은 아니다. 프로젝트의 수 만큼 다양한 경우의 수가 존재하기 때문에 하나의 방법만 고집할 수는 없다. 이 글이 그 정답을 찾기 위한 과정에서 도움이 되었으면 좋겠다.
먼 길을 가도 그 시작은 첫 발을 내딛는 일에서 시작한다. 이전의 코드 기반에서 여전히 작업하고 있고, 그 코드 양이 너무 많다 하더라도 점진적으로 코드를 개선할 수 있는 방법이 있다. 여기에서 다룰 내용은 모던 PHP를 도입하기 위해 회사에서 작업했던 작은 부분을 정리한 것이다. 코드를 개선하면서 전혀 지식이 없는 구성원도 자연스레 학습할 수 있도록 학습 곡선을 완만하게 만들기 위해 노력했던 부분도 함께 정리해보려고 한다. 가장 먼저 뷰를 분리하는 것에 대해 다뤄보려고 한다.
뷰 분리하기
코드를 분리해서 작성하는 과정은 중요하다. 각 코드가 서로에게 너무 의존적이거나 한 쪽이 다른 한 쪽을 너무 잘 아는 경우에는 코드 재사용도 어렵고 제대로 구동되는지 확인하기도 어렵다. PHP는 언어적인 특징 때문인지 몰라도 뷰 부분이 특히 심하게 붙어있는 모습을 자주 발견할 수 있다.
MVC 패턴을 사용하는 PHP 프레임워크 또는 플랫폼을 사용하는 프로젝트라면 별도로 뷰를 분리하는 노력 없이도 자연스럽게 로직과 뷰를 구분해서 작성할 수 있다. 하지만 여전히 많은 PHP 프로젝트는 echo로 HTML 문자열을 직접 출력하거나 include를 사용해서 별도의 파일을 불러오는 방식으로 개발되어 있다. 예를 먼저 확인해 보자.
이 코드를 보면 앞서 방식보다는 뷰가 분리된 것처럼 보인다. 하지만 이 코드는 뷰를 분리했다기 보다는 두개의 PHP 파일로 나눠서 작성하는 방식에 가깝다.
여기서 살펴본 두 경우는 이전에 작성된 코드라면 쉽게 찾을 수 있는 방식이다. 빠르고 간편하게 작성할 수 있을지 몰라도 재사용성이 높지 않고 관리가 쉽지 않다. 그나마 두 번째 방식은 분리되어 있지만 그렇다고 편리하다고는 할 수 없는 구석이 많다. 왜 이렇게 작성된 코드는 불편한 것일까?
전자의 경우는 외부의 함수를 그대로 사용하고 있어서 뷰의 의존도가 높다. 함수의 반환 값이나 사용 방식이 달라지면 뷰에서 해당 함수를 사용한 모든 위치를 찾아서 변경해야 할 것이다. 그리고 이렇게 생성된 html을 다른 곳에서 다시 사용하기는 쉽지 않다. 이 파일을 다른 파일에서 불러오게 되면 파일 내에 포함되어 있는 모든 기능을 호출하게 된다. 이 파일을 다시 사용하더라도 작성했을 당시의 의도를 바꾸기 어렵다.
그래도 후자의 경우는 뷰가 분리되어 있어서 뷰를 다시 사용하는 것은 가능하게 느껴진다. 하지만 뷰에서 전역 변수에 접근하는 방식으로 데이터에 접근하고 있다. 이런 상황에서는 뷰에서 어떤 변수를 사용하고 있는지 뷰 코드를 들여다보기 전까지는 알기 어렵다. 이런 방식으로 뷰를 재사용하게 되면 해당 파일을 include 하기 전에 어떤 변수를 php 내부에서 사용하고 있는지 살펴본 후, 모두 전역 변수로 선언한 다음 include를 수행해야 한다.
결과를 예측할 수 없는 코드
PHP에서는 결과를 출력하는데 수고가 전혀 필요 없다. 위 코드에서 보는 것처럼 <?php ?>로 처리되지 않은 부분과 echo를 사용해서 출력한 부분은 바로 화면에 노출되기 때문이다. 이 특징은 짧은 코드를 작성할 때 큰 고민 없이 빠르게 작성할 수 있도록 하지만 조금이라도 규모가 커지기 시작하면 관리를 어렵게 만든다.
앞에서 확인한 예제처럼 작성한 PHP 코드가 점점 관리하기 어렵게 변하는 이유는 바로 출력되는 결과를 예측하는 것이 불가능하다는 점 에서 기인한다. (물론 e2e 테스트를 수행할 수 있지만 이런 코드를 작성하는 곳에서 e2e 테스트를 사용한다면 특수한 경우다.) 두 파일에서 출력하는 내용은 변수로 받은 후 출력 여부를 결정하는 흐름이 존재하지 않는다. 전자는 데이터를 직접 가져와서 바로 출력하고 있고 후자는 가져올 데이터를 전역 변수를 통해 접근하고 있다. 개발자의 의도에 따라서 통제되는 방식이라고 하기 어렵다. 오히려 물감을 가져와서 종이 위에 어떻게 뿌려지는지 쏟아놓고 보는 방식에 가깝다. 이전 코드를 사용하는 PHP는 대부분 일단 코드를 쏟은 후에 눈과 손으로 직접 확인하는 경우가 많다. 이는 코드가 적을 경우에 문제 없지만 커지면 그만큼 번거로운 일이 된다. 결국에는 통제가 안되는 코드를 수정하는 일은 꺼림칙하고 두려운 작업이 되고 만다.
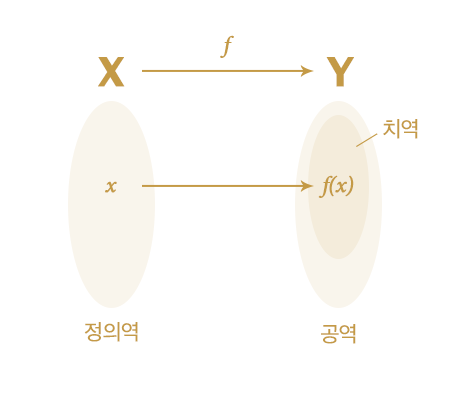
함수에 대해 생각해보자. 프로그래밍을 하게 되면 필연적으로 함수를 작성하게 된다. 함수는 인자로 값을 입력하고, 가공한 후에 결과를 반환한다. 대부분의 함수는 특수한 용도가 아닌 이상에는 같은 값을 넣었을 때 항상 같은 결과를 반환한다. 수학에서는 함수에 인자로 전달할 수 있는 값의 집합을 정의역으로, 결과로 받을 수 있는 값의 집합을 치역으로 정의한다. 프로그래밍에서의 함수도 동일하게 입력으로 사용할 수 있는 집합과 그 입력으로 출력되는 결과 값 집합이 존재한다. 즉, 입력의 범위를 명확히 알면 출력되는 결과물도 명확하게 알 수 있다는 뜻이다.
수학에서의 함수
뷰를 입력과 출력이 존재하는 함수라는 관점에서 생각해보자. 위에서 작성했던 코드를 다시 보면 $session과 $users를 입력받고 html로 변환한 값을 반환하는 함수로 볼 수 있다. 함수 형태로 뷰를 사용한다면 뷰에서 사용할 변수를 인자로 사용할 수 있어서 입력을 명확하게 통제할 수 있다. 앞서 본 함수의 특징처럼 이 뷰 함수도 입력에 따라 그 결과인 html을 예측할 수 있게 된다. 다시 말해, 그동안 사용한 뷰를 함수처럼 바꾼다면 입력과 출력의 범위를 명확하게 파악할 수 있게 되는 것이다.
php의 뷰 함수
뷰 함수로 전환하기
간단하게 뷰를 불러오는 함수를 구현해보자. 파일을 불러오더라도 출력하는 결과를 예측할 수 있도록 만들 수 있다. 다음처럼 include로 불러온 내용을 결과로 반환하도록 작성한다.
<?php
function view($template) {
if (is_file($template)) {
ob_start();
include $template;
return ob_get_clean();
}
return new Exception("Template not found");
}
?>
출력 버퍼를 제어하는 함수 ob_start(), ob_get_clean()을 사용해서 불러온 결과를 반환했다. 이 함수를 사용해서 외부 파일을 불러와도 바로 출력되지 않고 변수로 받은 후 출력할 수 있게 되었다.
이렇게 불러온 php 파일은 함수 내에서 불러왔기 때문에 함수 외부에 있는 전역 변수에 접근할 수 없다. 함수 스코프에 의해 전역 변수로부터 통제된 환경이 만들어진 것이다. 덕분에 외부의 영향을 받지 않는 방식으로 php 파일을 불러올 수 있게 되었다.
이제 뷰 파일 내에서 사용하려는 변수를 뷰 함수의 인자로 넘겨주려고 한다. 넘어온 변수를 해당 php 파일을 불러오는 환경에서 사용할 수 있도록 다음처럼 함수를 수정한다.
<?php
function view($template, $data = []) {
if (is_file($template)) {
ob_start();
extract($data);
include $template;
return ob_get_clean();
}
return new Exception("Template not found");
}
?>
$data로 외부 값을 배열로 받은 후에 extract() 함수를 사용해서 내부 변수로 전환했다. 새로 작성한 함수를 사용한 예시다.
<?php // templates/dashboard.php ?>
<?php if ( isset($user) ): ?>
<div>Welcome, <?php echo $user['nickname'];?>!</div>
<?php else: ?>
<div>I don't know who you are. Welcome, Stranger!</div>
<?php endif; ?>
여기서 사용한 뷰 함수는 간단한 예시로, 뷰를 불러오는 환경을 보여주기 위한 예제에 불과하다. 실제로 사용하게 될 때는 레이아웃 내 다양한 계층과 구성 요소를 처리해야 하는 경우가 많다. 이럴 때는 이 함수로는 부족하며 이런 함수 대신 다양한 환경을 고려해서 개발된 템플릿 패키지를 적용하는 게 바람직하다.
템플릿 패키지 사용하기
다양한 PHP 프레임워크는 각자 개성있고 많은 기능을 가진 템플릿 엔진을 사용하고 있다. Laravel은 Blade, Symfony는 Twig을 채택하고 있다. 모두 좋은 템플릿 엔진이고, PHP와는 다르게 독자적인 문법을 채택해서 작성하는 파일이 뷰의 역할만 할 수 있도록 PHP 전체의 기능을 제한하고 최대한 뷰 역할을 수행하도록 적절한 문법을 제공한다. 이런 템플릿 엔진을 사용할 수 있는 환경이라면 편리하고 가독성 높은 템플릿 문법을 사용할 수 있다.
프레임워크를 사용하지 않는 환경이라면 이런 템플릿 엔진이 학습 곡선을 더한다는 인상을 받을 수 있으며 같이 유지보수 하는 사람에게 부담을 줄 수도 있다. 이런 경우에는 PHP를 템플릿으로 사용하는 템플릿 엔진을 선택할 수 있다. 사용하는 템플릿이 여전히 PHP 파일과 같은 문법을 사용하면서도 앞에서 작성해본 뷰 함수와 같이 통제된 환경을 제공할 수 있는 패키지가 있다. 여기서는 Plates를 사용해서 앞에서 작성한 코드를 수정해볼 것이다.
먼저 Plates를 composer로 설치한다.
$ composer require league/plates
그리고 php 앞에서 autoload.php를 불러와 내려받은 plates를 사용할 수 있도록 한다.
<?php // dashboard.php
require_once('vendor/autoload.php');
require_once('lib.php');
// templates을 기본 경로와 함께 초기화
$templates = new League\Plates\Engine('templates');
$session = get_session();
if ( $session->is_logged_in() ) {
$user = get_user($session->get_current_user_id());
} else {
$user = null;
}
// 앞서 view 함수처럼 사용
echo $templates->render('dashboard', [ 'user' => $user ]);
Plates는 레이아웃, 중첩, 내부 함수 사용이나 템플릿 상속 등 편리한 기능을 제공한다. 자세한 내용은 Plates의 문서를 확인한다.
정리
지금까지 뷰를 분리하는 과정을 간단하게 살펴봤다. MVC 프레임워크처럼 구조가 잘 잡힌 코드를 사용하는 것이 가장 바람직하겠지만, 점진적으로 코드를 개선하려면 여기서 살펴본 방식대로 뷰를 먼저 분리하는 것부터 작게 시작할 수 있다.
뷰 함수 또는 템플릿 엔진을 사용해서 외부 환경의 영향을 받지 않는 독립적인 뷰를 만들 수 있다. 뷰가 결과로 반환되기 때문에 출력 범위를 예측하고 테스트 할 수 있게 된다. 또한 뷰에 집어넣는 값을 통제할 수 있다. 전역 변수 접근을 차단하는 것으로 외부 요인의 영향을 최대한 줄일 수 있다.
그리고 새로운 내용을 배우거나 도입하는데 거리낌이 있는 경우라도 타 템플릿 엔진과 달리 Plates 같은 템플릿 엔진은 PHP 로직을 그대로 사용할 수 있기 때문에 상대적으로 자연스럽게 도입할 수 있다.
이상적인 상황을 가정해보면 이 패키지를 composer를 사용해서 설치하는 것으로 새로운 개발 흐름에 조금씩 관심을 갖게 만들 수 있고 새로운 패키지를 도입하는 것에 대해 좋은 인상을 남길 수 있다. 또한 추후에 MVC 프레임워크를 도입해도 뷰를 분리해서 작성하는 방식에 자연스럽게 녹아들 수 있을 것이다.
함수의 호출 결과를 캐시로 만드는 @memoize 데코레이터 설명. 캐시 상황에서 문제 해결하기, 번역.
파이썬에서 데코레이터를 정말 자주 사용하고 있지만 다양한 용례는 접해보지 못했었다. Ned Batchelder의 글 Isolated @memoize은 @memoize 데코레이터에 대한 이야기인데 같이 곁들여진 설명과 각 링크가 유익해서 번역했다. 파이썬 데코레이터 모음 위키 페이지도 살펴보면 좋겠다.
파이썬 @memoize 고립된 환경에서 사용하기
실행 비용이 비싼 함수를 호출한다고 생각해보자. 동일한 입력을 했을 때 동일한 결과를 반환하는 함수인 경우에는 사람들 대부분은 @memoize 데코레이터를 사용하는 것을 선호한다. 이 데코레이터는 이전에 실행한 적이 있는 경우에는 동일한 결과를 빠르게 내놓을 수 있도록 캐시해둔다. 다음은 @memoize 구현 모음을 차용해서 만든 간단한 코드다.
def memoize(func):
cache = {}
def memoizer(*args, **kwargs):
key = str(args) + str(kwargs)
if key not in cache:
cache[key] = func(*args, **kwargs)
return cache[key]
return memoizer
@memoize
def expensive_fn(a, b):
return a + b # 물론 이 함수는 그렇게 비싼 연산이 아니다!
이 코드는 원하는 동작을 제대로 수행하는 좋은 코드다. expresive_fn 함수를 동일한 인자로 반복해서 호출하면 실제로 함수를 호출하지 않고 캐시된 값을 사용할 수 있다.
하지만 여기에는 잠재적인 위험이 있다. 캐시 딕셔너리가 전역이라는 점이다. 물론 이 말을 문자 그대로 전역이라고 생각하는 잘못을 범하지 말자. global 키워드를 사용하지 않았고 모듈 단위의 변수인 것도 아니다. 하지만 이 딕셔너리는 프로세스 전체에서 expensive_fn를 대상으로 오직 하나의 캐시 딕셔너리를 갖고 있기 때문에 이 관점에서는 전역 변수라고 말할 수 있을 것이다.
전역은 잘 짜여진 테스트를 방해할 수 있다. 자동화된 테스트에서 가장 이상적인 동작 방식은 각 테스트가 서로 영향을 미치지 않도록 고립된 형태로 테스트를 수행하는 것이다. test1에서 어떤 일이 일어나든지 test99에는 영향이 없어야 한다. 하지만 여기서 test1부터 test99까지 expensive_fn을 (1, 2) 인자를 사용해서 호출했다면 test1은 함수를 호출하지만 test99는 캐시에 저장된 값을 사용한다. 더 나쁜 부분은 전체 테스트를 호출하면 test99는 캐시에 저장된 값을 사용하게 될 것인 반면 test99만 실행하면 함수를 실제로 실행하게 된다는 점이다.
만약 expensive_fn이 정말로 부작용 없는 순수 함수라면 이런 특징이 문제가 되지 않을 것이다. 하지만 때로는 문제가 되는 경우도 있다.
내가 관리하게 된 프로젝트 중에 고정된 데이터를 가져오기 위해 @memoize를 사용하는 웹사이트가 있었다. 자료를 가져올 때 단 한 번만 가져왔기 때문에 @memoize는 적절했고 프로그램을 사용하는데 전혀 문제가 되질 않았다. 테스트는 Betamax를 사용해서 네트워크 접근을 모조로 만들었다.
Betamax는 대단한 라이브러리다. 각 테스트 케이스를 구동할 때 각 테스트에서의 네트워크 접근을 확인한 후, “카세트”에 요청과 반환을 JSON 양식으로 저장한다. 다시 테스트를 수행하면 카세트에 저장되어 있는 정보를 사용해서 네트워크 접근을 모조해서 처리해준다.
문제는 test1의 카세트에서 캐시로 저장될 자원을 네트워크로 요청하게 되고 test99는 @memoize로 인해 네트워크를 통해 데이터를 요청할 필요가 없어졌기 때문에 test99의 카세트가 제대로 생성이 되지 않는다. 이제 테스트를 test99만 구동했을 때 카세트에 저장된 정보가 없기 때문에 테스트가 실패하게 된다. test1과 test99는 각각 고립되서 실행된다고 볼 수 없다. 저장된 캐시를 통해서 전역적으로 값을 공유하기 때문이다.
내 해결책은 @memoize를 사용했을 때 테스트 사이에 캐시 내용을 지우는 방식이다. 이 코드를 직접 작성하기 보다는 functools에 포함되어 있는 lru_cache 데코레이터를 사용할 수 있다. (여전히 2.7 버전의 파이썬을 사용하고 있다면 functools32을 찾아보자.) 이 데코레이터는 전역 캐시의 모든 값을 지울 수 있는 .cache_clear 함수를 제공한다. 이 함수는 각 데코레이터를 사용한 함수에 있기 때문에 사용한 함수를 목록으로 갖고 있어야 한다.
import functools
# memoize를 사용한 함수 목록을 저장. 그런 후
# `clear_memoized_values`로 일괄 비우기를 수행.
_memoized_functions = []
def memoize(func):
"""함수를 호출해서 반환한 값을 캐시로 저장함"""
func = functools.lru_cache()(func)
_memoized_functions.append(func)
return func
def clear_memoized_values():
"""@memoize에 저장된 모든 값을 비워서 각 테스트가 고립된 환경으로 동작할 수 있도록 함"""
for func in _memoized_functions:
func.cache_clear()
이제 각 테스트 전에 캐시를 비우기 위해 py.test의 픽스쳐에서, 또는 테스트 케이스의 setUp() 메서드에서 clear_memoized_values() 함수를 사용할 수 있다.
# py.test를 사용하는 경우
@pytest.fixture(autouse=True)
def reset_all_memoized_functions():
"""@memoize에 캐시로 저장된 값을 매 테스트 전에 비움"""
clear_memoized_values()
# unittest를 사용하는 경우
class MyTestCaseBase(unittest.TestCase):
def setUp(self):
super().setUp()
clear_memoized_values()
사실 @memoize를 사용하는 다양한 이유를 보여주는 것이 더 나을지도 모른다. 순수 함수는 모든 테스트에서 캐시를 사용해서 같은 값을 반환해도 문제가 없을 것이다. 연산이 필요한 경우라면 누가 이런 문제를 신경 쓸까? 하지만 다른 경우에서는 확실히 고립된 환경을 만들어서 사용해야 한다. @memoize는 마술이 아니다. 이 코드가 어떤 일을 하는지, 어떤 상황에서 더 제어가 필요한지 잘 알아야 한다.
파이썬을 처음 공부할 때 리스트와 튜플에 대해 비슷한 의문을 가진 적이 있었다. 이 둘을 비교하고 설명하는 Ned Batchelder의 Lists vs. Tuples 글을 번역했다. 특별한 내용은 아니지만 기술적인 차이와 문화적 차이로 구분해서 접근하는 방식이 독특하게 느껴진다.
Python에 입문하는 사람들이 흔하게 하는 질문이 있다. 리스트(list)와 튜플(tuple)의 차이는 무엇인가?
이 질문의 답변은 이렇다. 이 두 타입은 각각 상호작용에 있어 두 가지 다른 차이점이 존재한다. 바로 기술적인 차이와 문화적인 차이다.
먼저 두 타입의 공통점을 확인하자. 리스트와 튜플은 둘 다 컨테이너로 일련의 객체를 저장하는데 사용한다.
둘 다 타입과 상관 없이 일련의 요소(element)를 갖을 수 있다. 두 타입 모두 요소의 순서를 관리한다. (세트(set)나 딕셔너리(dict)와 다르게 말이다.)
이제 차이점을 보자. 리스트와 튜플의 기술적 차이점은 불변성에 있다. 리스트는 가변적(mutable, 변경 가능)이며 튜플은 불변적(immutable, 변경 불가)이다. 이 특징이 파이썬 언어에서 둘을 구분하는 유일한 차이점이다.
>>> my_list[1] = "two"
>>> my_list
[1, 'two', 3]
>>> my_tuple[1] = "two"
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'tuple' object does not support item assignment
이 특징은 리스트와 튜플을 구분하는 유일한 기술적 차이점이지만 이 특징이 나타나는 부분은 여럿 존재한다. 예를 들면 리스트에는 .append() 메소드를 사용해서 새로운 요소를 추가할 수 있지만 튜플은 불가능하다.
>>> my_list.append("four")
>>> my_list
[1, 'two', 3, 'four']
>>> my_tuple.append("four")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'tuple' object has no attribute 'append'
튜플은 .append() 메소드가 필요하지 않다. 튜플은 수정할 수 없기 때문이다.
문화적인 차이점을 살펴보자. 리스트와 튜플을 어떻게 사용하는지에 따른 차이점이 있다. 리스트는 단일 종류의 요소를 갖고 있고 그 일련의 요소가 몇 개나 들어 있는지 명확하지 않은 경우에 주로 사용한다. 튜플은 들어 있는 요소의 수를 사전에 정확히 알고 있을 경우에 사용한다. 동일한 요소가 들어있는 리스트와 달리 튜플에서는 각 요소의 위치가 큰 의미를 갖고 있기 때문이다.
디렉토리 내에 있는 파일 중 *.py로 끝나는 파일을 찾는 함수를 작성한다고 가정해보자. 이 함수를 사용했을 때는 파일을 몇 개나 찾게 될 지 알 수 없다. 그리고 동일한 규칙으로 찾은 파일이기 때문에 항목 하나 하나가 의미상 동일하다. 그러므로 이 함수는 리스트를 반환할 것이다.
(지금은 클래스를 사용하는 것에 대해서 이야기하지 않을 것이다.) 이 튜플에서 첫 요소는 식별번호, 두 번째는 도시… 순으로 작성했다. 튜플에서의 위치가 담긴 내용이 어떤 정보인지를 나타낸다.
C 언어에서 이 문화적 차이를 대입해보면 목록은 배열(array) 같고 튜플은 구조체(struct)와 비슷할 것이다.
파이썬은 네임드튜플(namedtuple)을 제공하는데 이 네임드튜플을 사용하면 튜플에서 각 위치의 의미를 명시적으로 작성할 수 있다.
>>> from collections import namedtuple
>>> Station = namedtuple("Station", "id, city, state, lat, long")
>>> denver = Station(44, "Denver", "CO", 40, 105)
>>> denver
Station(id=44, city='Denver', state='CO', lat=40, long=105)
>>> denver.city
'Denver'
>>> denver[1]
'Denver'
튜플과 리스트의 문화적 차이를 영악하게 정리한다면 튜플은 네임드튜플에서 이름이 없는 것이라고 할 수 있다.
기술적 차이점과 문화적 차이점을 연계해서 생각하기란 쉽지 않은데 종종 이 차이점이 이상할 때가 있기 때문이다. 왜 단일 종류의 일련 데이터는 가변적이고 여러 종류의 일련 데이터는 불변이어야 하는 것일까? 예를 들면 앞에서 저장했던 기상관측소의 데이터는 수정할 수 없다. 네임드 튜플은 튜플이고 튜플은 불변이기 때문이다.
>>> denver.lat = 39.7392
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: can't set attribute
때때로 기술적인 고려가 문화적 고려를 덮어쓰는 경우가 있다. 리스트를 딕셔너리에서 키로 사용할 수 없다. 불변 값만 해시를 만들 수 있기 때문에 키에 불변 값만 사용 가능하다. 대신 리스트를 키로 사용하고 싶다면 다음 예처럼 리스트를 튜플로 변경했을 때 사용할 수 있다.
>>> d = {}
>>> nums = [1, 2, 3]
>>> d[nums] = "hello"
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: unhashable type: 'list'
>>> d[tuple(nums)] = "hello"
>>> d
{(1, 2, 3): 'hello'}
기술과 문화가 충돌하는 또 다른 예가 있다. 파이썬에서도 리스트가 더 적합한 상황에서 튜플을 사용하는 경우가 있다. *args를 함수에서 정의했을 때, args로 전달되는 인자는 튜플을 사용한다. 함수를 호출할 때 사용한 인자의 순서가 크게 중요하지 않더라도 말이다. 튜플은 불변이고 전달된 값은 변경할 수 없기 때문에 이렇게 구현되었다고 말할 수 있겠지만 그건 문화적 차이보다 기술적 차이에 더 가치를 두고 설명하는 방식이라 볼 수 있다.
물론 *args에서 위치는 매우 큰 의미를 갖는다. 매개변수는 그 위치에 따라 의미가 크게 달라지기 때문이다. 하지만 함수는 *args를 전달 받고 다른 함수에 전달해준다고만 봤을 때 *args는 단순히 인자 목록이고 각 인자는 별 다른 의미적 차이가 없다고 할 수 있다. 그리고 각 함수에서 함수로 이동할 때마다 그 목록의 길이는 가변적인 것으로 볼 수 있다.
파이썬이 여기서 튜플을 사용하는 이유는 리스트에 비해서 조금 더 공간 효율적이기 때문이다. 리스트는 요소를 추가하는 동작을 빠르게 수행할 수 있도록 더 많은 공간을 저장해둔다. 이 특징은 파이썬의 실용주의적 측면을 나타낸다. 이런 상황처럼 *args를 두고 리스트인지 튜플인지 언급하기 어려운 애매할 때는 그냥 상황을 쉽게 설명할 수 있도록 자료 구조(data structure)라는 표현을 쓰면 될 것이다.
대부분의 경우에 리스트를 사용할지, 튜플을 사용할지는 문화적 차이에 기반해서 선택하게 될 것이다. 어떤 의미의 데이터인지 생각해보자. 만약 프로그램이 실제로 다루는 자료가 다른 길이의 데이터를 갖는다면 분명 리스트를 써야 할 것이다. 작성한 코드에서 세 번째 요소에 의미가 있는 경우라면 분명 튜플을 사용해야 할 상황이다.
반면 함수형 프로그래밍에서는 코드를 어렵게 만들 수 있는 부작용을 피하기 위해서 불변 데이터 구조를 사용하라고 강조한다. 만약 함수형 프로그래밍의 팬이라면 튜플이 제공하는 불변성 때문에라도 분명 튜플을 좋아하게 될 것이다.
자, 다시 질문해보자. 튜플을 써야 할까, 리스트를 사용해야 할까? 이 질문의 답변은 항상 간단하지 않다.